‚So clever I don’t understand a word of what I am saying‘ – Das Potenzial der KI im Umgang mit textbasierten Daten ist bei weitem nicht grenzenlos

Die oft geäusserte Angst, dass KI-Roboter kurz davor sind, in jeden Bereich unseres Lebens einzudringen und die Kontrolle zu übernehmen, ist zugegebenermassen verständlich, wenn man bedenkt, welche Fähigkeiten der KI bereits heute nachgesagt werden: Gastbeiträge für Zeitungen, Kundendienstanfragen bearbeiten, medizinische Diagnosen stellen, langjährige Fragestellungen der Biologiewissenschaften beantworten und vieles mehr – will man den Quellen Glauben schenken [1], [2]. Aber sind diese vermeintlichen Erfolge tatsächlich ein Beweis für unbegrenztes Potenzial? Werden KI-Systeme wirklich in der Lage sein, jede Aufgabe zu lösen, wenn sie nur genügend Zeit und Daten haben? Sie wollen das vielleicht nicht hören, aber die Antwort ist ein ganz klares NEIN. Zumindest nicht, wenn Forschung und Entwicklung an den rein datenbasierten Ansätzen festhalten, auf die sie derzeit so fixiert sind.
Zunächst einmal ist die künstliche Intelligenz nicht im Entferntesten mit menschlicher Intelligenz vergleichbar. Jedes KI-System ist eine ausgeklügelte Trickkiste, die uns Menschen vorgaukeln soll, dass das System die vorgelegte Aufgabe irgendwie versteht. Um also KI-Technologien zu entwickeln, die in irgendeinem Sinne intelligent sind, führt kein Weg daran vorbei, diese Technologien mit umfangreichem menschlichem Wissen zu füttern – was ein erhebliches Mass an menschlicher Arbeit erfordert und in absehbarer Zukunft auch erfordern wird. Infolgedessen – und auch das werden Sie womöglich nicht hören wollen – ist es eine schlicht eine Fehlinvestition, sich auf Softwarelösungen im HR- und Arbeitsmarktmanagement zu verlassen, die ausschliesslich auf Deep Learning (DL) oder anderen statistischen/Machine-Learning (ML) Ansätzen basieren. Und es ist nicht nur eine Geldverschwendung, sondern auch eine Frage der Ethik: Gerade im HR-Bereich ist die Verlässlichkeit von Daten und Auswertungen von entscheidender Bedeutung, da sie das Leben realer Menschen nachhaltig beeinflussen können. Allzu oft werden beispielsweise durchaus geeignete Kandidaten von KI-basierten Systemen wie ATS aussortiert, nur weil ihr Lebenslauf nicht exakt die im Filter angegebenen Schlüsselwörter enthält oder diese mit ‘falschen’ Zusammenhängen verbunden werden. Dies ist nur eines von vielen Beispielen dafür, wie echte Menschen von unzulänglicher KI betroffen sein können.
Künstlich – im Sinne von «fake»
Während Forscher KI-Systeme als solche definieren, die ihr Umfeld wahrnehmen und Massnahmen ergreifen, um die Chancen auf das Erreichen ihrer Ziele maximieren, ist die populäre Vorstellung von KI, dass sie sich der menschlichen Kognition annähern soll. Intelligenz wird in der Regel als die Fähigkeit definiert, zu lernen, zu verstehen und Urteile zu fällen oder Meinungen zu bilden, die auf Vernunft basieren, oder mit neuen oder schwierigen Situationen umzugehen. Die erfordert allerdings eine kognitive Schlüsselfähigkeit: das Speichern und Anwenden von sogenanntem Weltwissen (commonsense knowledge), also allgemeines Wissen, Kenntnisse und Erfahrungen über Umwelt und Gesellschaft. Wir Menschen eignen uns Weltwissen durch eine Kombination aus Lernen und Erfahrungen an. KI-Systeme sind hierzu bis jetzt schlicht nicht in der Lage und werden es in absehbarer Zeit auch nicht sein. Am deutlichsten werden diese Einschränkungen bei Methoden der Computerlinguistik zu NLP (natural language processing) und NLU (natural language understanding), die auf ML basieren. Denn Weltwissen ist absolut unerlässlich für das Verständnis natürlicher Sprache. Betrachten wir als Beispiel die folgende Aussage:
Charlie hat den Bus gegen einen Baum gefahren.
Nirgends in diesem Satz steht ausdrücklich, dass Charlie ein Mensch ist, dass dieser Mensch im Bus sass oder dass dies ein ungewöhnliches Verhalten ist. Und doch können wir dank unserem Alltagswissen ohne grosse Mühe diese und viele andere Schlussfolgerungen aus diesem einfachen Satz ziehen. Diese vom Linguisten Noam Chomsky als «Sprachkompetenz» bezeichnete Fähigkeit unterscheidet auf NLP und NLU trainierte Computersysteme grundlegend von der menschlichen Kognition. Während wir Menschen diese Sprachkompetenz bereits in jungen Jahren erwerben und dank dieser die Bedeutung beliebiger sprachlicher Ausdrücke erkennen können, werden rein datenbasierte KI-Modelle dies nie in gleichem Masse schaffen, da sie auf rein quantitativer Basis arbeiten: Ihre «Intelligenz» basiert auf statistischen Annäherungen und (teils sinnlosem) Auswendiglernen textbasierter Daten. ML_Systeme können zwar das Problem des Verstehens bisweilen umgehen und den Eindruck erwecken, dass sie sich intelligent verhalten – vorausgesetzt, sie werden mit genügend Daten gefüttert und die Aufgabe ist ausreichend eingegrenzt. Aber sie werden die Bedeutung von Wörtern nie wirklich verstehen; dazu fehlt ihnen schlicht die Verbindung zwischen Form (Sprache) und Inhalt (Bezug zur realen Welt) [1].
Genau deshalb kämpfen selbst die fortschrittlichsten KI-Modelle immer noch mit dieser Art von Aussagen: weil sie so viele implizite, oft wichtige Informationen und Kausalitäten beinhalten. So war beispielsweise GPT-3, ein hochmodernes KI-basiertes Sprachmodell (das den eingangs zitierten Zeitungsartikel verfasst hat), nicht in der Lage, die einfache Frage, ob ein Toaster oder ein Bleistift schwerer ist, korrekt zu beantworten [1]. Dies erinnert ein wenig an ein Zitat aus Oscar Wildes Die vornehme Rakete: „I am so clever that sometimes I don’t understand a single word of what I am saying“…
Ein Hauptgrund für diese Problematik liegt darin, dass Weltwissen eine kaum vorstellbare Anzahl von Fakten darüber enthält, wie unsere Welt funktioniert. Wir Menschen haben diese Fakten durch gelebte Erfahrung verinnerlicht und können sie beim Ausdrücken und Verstehen von Sprache einsetzen, ohne diese erstaunliche Fülle an Wissen je in schriftlicher Form festhalten zu müssen. Und gerade weil dieses implizite Wissen nicht systematisch erfasst wird, haben KI-Systeme keinen Zugang dazu – zumindest rein datenbasierte KI-Systeme nicht, Systeme also, die ausschliesslich auf statistischen/ML-Ansätzen basieren. Diese Systeme stehen vor unüberwindbaren Herausforderungen in Bezug auf Sprachverständnis. Denn sie ist «unerwartet».
Ein weiteres einfaches Beispiel: Bei einer statistischen Analyse von Wörtern, die mit dem englischen Wort pen (dt. Stift) verbunden sind, spuckt ein ML-System unter Umständen die Wörter Chirac und Jospin aus, weil diese Namen oft zusammen mit der französischen Politikerin Marie Le Pen genannt werden, welche natürlich nichts mit Schreibgeräten zu tun hat. Noch komplizierter wird es, wenn ein und derselbe Ausdruck je nach Kontext unterschiedliche Bedeutungen annimmt – zum Beispiel das Schloss. Rein auf ML basierende Systeme haben oft grosse Schwierigkeiten, die Nuancen solcher Alltagssprache zu erkennen, weil sie die Bedeutungen eines Wortes nicht speichern: die Verbindungen beruhen lediglich auf Koinzidenz, also gleichzeitiges Auftreten. In der rein datenbasierten Welt ist es also noch ein weiter Weg bis zur zuverlässigen NLU.
Keine KI ohne MI
Seit den 1950ern gibt es KI, und sie hat immer wieder Phasen des Hypes und der Desillusionierung durchlaufen. Derzeit befinden wir uns, zumindest in der Unterdisziplin NLU, wieder in der «Talsohle der Ernüchterung», wie Gartner es so treffend formuliert hat. Nichtsdestotrotz klammern sich viele noch an die grossen Versprechungen und veröffentlichen, preisen und investieren munter in rein datenbasierte KI-Technologien. Sich bei Anwendungen, die Sprachverständnis erfordern, vollständig auf ML-basierte Algorithmen zu verlassen, ist jedoch nichts als ein teurer Fehler. Wie wir bereits erläutert haben, ist es ein grosser Sprung von der automatisierten Verarbeitung von Textdaten (NLP) zum sinnvollen, menschenähnlichen Verstehen (NLU) dieser Information durch Maschinen. Daher werden viele Automatisierungspläne eine Illusion bleiben. Es ist höchste Zeit, auf ein Strategie umzusteigen, die diese anspruchsvollen Aufgaben erfolgreich bewältigen kann, indem sie künstliche Intelligenz effektiv durch menschliche Intelligenz erzeugt.
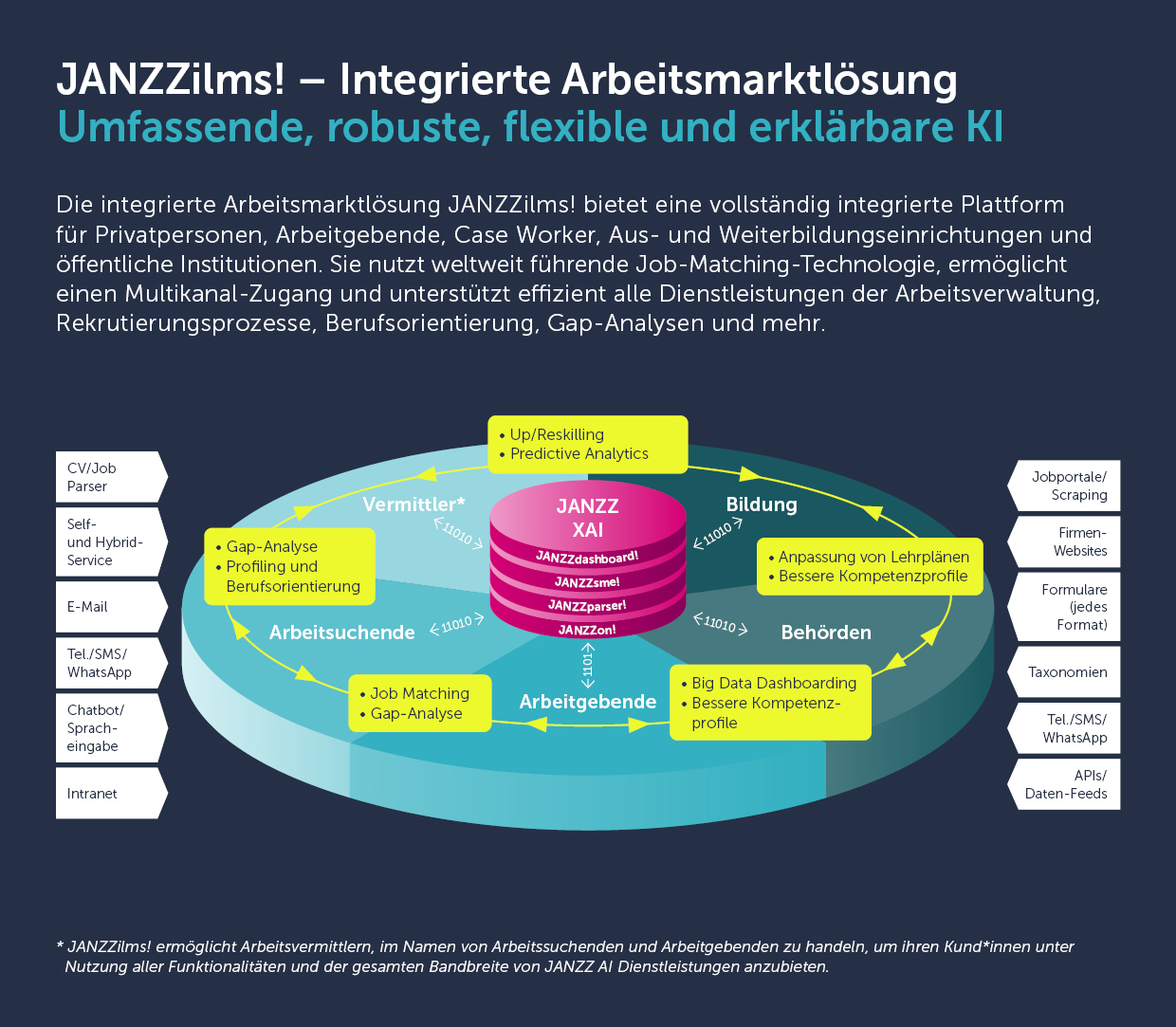
In unserem Kompetenzbereich hier bei JANZZ, dem (Re-)Strukturieren und Matching berufsbezogener Daten, wissen wir, dass viele automatisierte Aufgaben in Big Data ein erhebliches Mass an menschlicher Arbeit und Intelligenz erfordern. Unser Tool zum Parsen von Stellenanzeigen und Lebensläufen, JANZZparser!, seit jeher auf NLP und NLU – allerdings immer in Kombination mit menschlichem Input: Unsere Datenanalysten und Ontologie-Kuratoren trainieren sorgfältig und kontinuierlich die sprachspezifischen Deep-Learning-Modelle und passen sie immer wieder an. NLP-Aufgaben werden mit unserem hauseigenen, handverlesenen Korpus an Goldstandard-Trainingsdaten trainiert. Die geparsten Informationen werden standardisiert und kontextualisiert mithilfe unserer handkuratierten Ontologie JANZZon!, der weltweit umfassendsten mehrsprachigen Wissensdarstellung für berufsbezogene Daten. Diese maschinenlesbare Wissensbasis enthält Millionen von Konzepten wie Berufe, Skills, Spezialisierungen, Ausbildungen und Erfahrungen, die von unseren domänespezialisierten Kurator*innen entsprechend ihrer gegenseitigen Relationen manuell verknüpft werden. JANZZon! integriert sowohl datengestütztes Wissen aus echten Stellenanzeigen und Lebensläufen als auch Experteninformationen aus internationalen Taxonomien wie ESCO oder O*Net. Nur so können unsere Technologien ein Sprachverständnis entwickeln, das den Namen künstliche Intelligenz tatsächlich verdient. Generische Ausdrücke wie Flexibilität werden in den entsprechenden Kontext gesetzt, sei es im Sinne von Zeitmanagement, Denken, oder anderen Aspekten. Damit werden falsche Matches aufgrund von Überschneidungen im Wortlaut, aber nicht im Inhalt, wie etwa Research and Ontology Management Specialist mit Berufen wie in der untenstehenden Abbildung, in unseren wissensbasierten Systemen von den Matching-Ergebnissen ausgeschlossen. Durch die einzigartige Kombination von Technologie und menschlicher Intelligenz in maschinenlesbarer Form können bei der Verarbeitung berufsbezogener Daten äusserst genaue, zuverlässige und sprach- und kulturübergreifende Ergebnisse erzielt werden. Fehler wie im Beispiel mit dem Stift treten schlicht nicht auf, weil jeder Ausdruck konzeptionell mit den richtigen und relevanten Bedeutungen und Assoziationspunkten verknüpft ist.

Gutes Geld schlechtem hinterherwerfen
Dass wir mit unserer hybriden, wissensbasierten Methode, menschliche Intelligenz mit modernsten ML/DL-Methoden zu kombinieren, auf dem richtigen Weg sind, bestätigen nicht nur unsere eigenen Erfahrungen und die erfolgreiche Zusammenarbeit mit Unternehmen und öffentlichen Arbeitsverwaltungen (PES) weltweit, sondern wird auch von – nicht kommerziell-orientierten – NLU-Forschern allgemein anerkannt. Die skizzierten Probleme rund um die fehlende kognitive Komponente in rein datenbasierten KI-Systemen werden in den nächsten 50 Jahren nicht verschwinden. Sobald menschliche Sprache im Spiel ist, wird es immer unzählige Fälle geben, in denen ein dreijähriges Kind die richtige semantische Verbindung herstellen kann, während ein maschinell-gelerntes Tool entweder versagt oder dies nur mit absurd hohem Aufwand schafft. Obwohl wissensbasierte Systeme wie unsere zuverlässige und erklärbare Sprachanalyse liefern, sind sie in Ungnade gefallen, weil der manuelle Aufwand des Knowledge Engineering in der Forschung und Entwicklung als Flaschenhals empfunden wurde. Und die Suche nach anderen Möglichkeiten im Umgang mit der Sprachverarbeitung führte zum rein datenbasierten Paradigma. Heutzutage, unterstützt durch die immense Geschwindigkeit und Speicherkapazität von Computern, verlassen sich die meisten auf die Anwendung generischer ML-Algorithmen auf immer grössere Datensätze für sehr begrenzte Aufgaben. Seit diesem Paradigmenwechsel haben viele Entwickler*innen und Kund*innen viel Zeit und Geld in diese Systeme investiert. Da sie finanziell so stark eingebunden sind, sind sie oft schlicht nicht bereit zuzugeben, dass dieser Ansatz nicht die gewünschten Ergebnisse liefern kann, obwohl die Beweislage zunehmend ungünstig wird.
Doch der hybride, wissensbasierte Ansatz, bei dem ML-basierte Elemente mit von Menschen erstellten semantischen Wissensdarstellungen kombiniert werden, kann die Leistung von Systemen, die auf Sprachverständnis angewiesen sind, erheblich verbessern. In unserem Fall kann unsere Technologie mit diesem Ansatz die Fallstricke rein datenbasierter Systeme vermeiden, die auf unkontrollierten KI-Prozessen, simplem Schlüsselwortabgleich und sinnlosen Extraktionen von an sich kontextarmen und schnell veralteten Taxonomien basieren. Stattdessen können unsere Matching- und Analyselösungen auf die Smart Data zurückgreifen, die von unserer Ontologie erzeugt werden. Diese kontextbasierte, ständig aktualisierte Wissensdarstellung kann auf vielfältige Weise für intelligente Klassifizierungs-, Such-, Matching- und Parsing-Prozesse sowie zahllose weitere Prozesse im Bereich berufsbezogener Daten genutzt werden. Gerade im Bereich der HR-Analytik erzielen unsere Lösungen überdurchschnittliche Ergebnisse, die weit über der Leistungsfähigkeit vergleichbarer Angebote liegen. Dank der gelieferten Insights sind Arbeitgebende in der Lage, fundierte Entscheidungen im Talentmanagement und in der strategischen Personalplanung zu treffen – auf der Grundlage intelligenter, zuverlässiger Daten.
Tun Sie das Richtige und tun Sie es richtig
Nicht zuletzt gibt es noch die ethischen Bedenken bei der Anwendung von KI auf Textdaten. Es gibt zahlreiche Beispiele, die zeigen, was passiert, wenn der Einsatz von ML-Systemen schiefgeht. So löste 2016 der Chatbot eines Softwareherstellers eine öffentliche Kontroverse aus, weil er nach einem ungewollten, kurzen Training durch Internet-Trolle beinahe sofort begann, sexistische und rassistische Beleidigungen von sich gab, anstatt wie geplant die NLP-Technologie des Unternehmens auf unterhaltsame und interaktive Weise zu demonstrieren. Die Herausforderung, eine KI zu entwickeln, welche die moralischen Werte der Menschheit teilt und zuverlässig danach handelt, ist eine äusserst komplexe (und möglicherweise unlösbare) Aufgabe. Angesichts des Trends, ML-Systeme immer häufiger mit realen Verantwortlichkeiten zu betrauen, ist dies jedoch eine dringende und ernstzunehmende Angelegenheit. Gerade in Bereichen wie Justizvollzug, Kreditwesen oder eben HR ist ein inadäquater Einsatz von KI und ML besonders heikel. Das Talent- und Arbeitsmarktmanagement beispielsweise wirkt sich direkt auf das Leben von Menschen aus. Daher muss jede Entscheidung im Detail begründet werden können; fehlerhafte, voreingenommene oder jegliche Blackbox-Automatisierung mit direktem Einfluss auf wichtige Entscheidungen in diesen Bereichen muss ausgemerzt werden. Diesen Standpunkt vertritt auch die Europäische Kommission in ihrem Whitepaper zu KI und den damit verbundenen zukünftigen Regulierungen, insbesondere im HR-Bereich. Tatsächlich würden fast alle hochgelobten KI-Systeme für Recruiting und Talentmanagement, die aktuell auf dem Markt sind – und vor allem aus den USA stammen – unter diesen geplanten Vorschriften hochkant durchfallen. Der Ansatz von JANZZ.technology ist derzeit der Einzige, der mit diesen regulatorischen Anpassungen kompatibel sein wird. Und dies hat sehr viel mit unserer Wissensdarstellung zu tun, die es uns ermöglicht, nicht nur eine KI-Technologie zu entwickeln, die dem Verstehen von Sprache sehr nahekommt, sondern eine tatsächlich erklärbare KI. Der Weg in die Zukunft besteht also letztlich in der Erkenntnis – in den Worten der NLU-Forscherin McShane: Es gibt keinen Flaschenhals, sondern einfach nur Arbeit, die getan werden muss.
Hier bei JANZZ.technology haben wir diese Arbeit für Sie bereits erledigt, dank Expert*innen mit diversem Hintergrund in Bezug auf Sprache, Erfahrung, Bildung, und Kultur. Ihr gebündeltes Wissen fliesst in unsere Ontologie JANZZon! ein und wird sowohl für Maschinen als auch für Menschen lesbar und verarbeitbar gemacht. Gemeinsam haben unsere Kurator*innen die bestmögliche und umfassendste Darstellung der stetig wachsenden Heterogenität des berufsbezogenen Wissens im Bereich von HR und Arbeitsmarktverwaltung. Dies ermöglicht mehrsprachige, modulare und vorurteilsfreie Lösungen für alle HR-Prozesse – und bringt Sie einen Schritt näher an wirklich intelligente HR- und Arbeitsmarktmanagement-Lösungen. Wenn Sie mehr über unsere Expertise und unsere Produkte erfahren oder von einer auf Ihre individuelle Situation zugeschnittenen Beratung profitieren möchten, kontaktieren Sie uns unter info@janzz.technology oder via Kontaktformular, besuchen Sie unsere Produktseite für öffentliche Arbeitsverwaltungen und folgen Sie unserer neuen Podcast-Serie.
[1] Toews, Rob. 2021. What Artificial Intelligence Still Can’t Do. URL: https://www.forbes.com/sites/robtoews/2021/06/01/what-artificial-intelligence-still-cant-do/amp/
[2] GPT-3 (Guardian). 2020. A robot wrote this entire article. Are you scared yet, human? URL: https://www.theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3