The poison apple of “easy” skills data – are you ready to give up that sweet taste?
This is the third in a series of posts about skills. If you haven’t already, read the other posts first:
Cutting through the BS and Sorry folks, but “Microsoft Office” is NOT a skill.
In the second post of this series, we discussed skills and the issues around defining and specifying them. Assuming we can reach some kind of common understanding of this valuable new currency, the next step is to find a way to generate meaningful skills and job data.
Shaky data – shaky results
Big data from online job platforms or professional networking sites can yield a wealth of information with a much higher granularity than the usual data gathered by national statistics offices in surveys – especially regarding skills. One reason is that, unlike printed advertisements, employers do not have to pay by space for online job postings and thus can provide more detailed information on the knowledge and skills they require. This online data also allows for a much larger sample to be monitored in real time, which can be highly valuable for analysts and policy makers to develop a timely and more detailed understanding of conditions and trends on the labor market.
However, when working with the data that is available online, such as online job advertisements (OJA) or professional profiles (e.g., LinkedIn profiles), we need to be clear on the fact that this data is neither complete nor representative and therefore any results must always be interpreted with caution. Not only because of the obvious fact that the results will be distorted, but more importantly because of the implications. Promoting certain skills based on distorted data can be harmful to the labor market: if workers focus on obtaining these skills – which by nature tend to be derived from data biased towards high-skilled professionals in sectors such as IT and other areas involving higher education – they are less likely to opt for career paths involving other skills that actually are in high demand, e.g., vocational careers in skilled trades, construction, healthcare, manufacturing, etc. Despite the fact that digitalization will primarily affect better educated workers with high wages in industrialized countries, simply because it is much easier to digitalize or automate at least some of the tasks in these jobs than those in many blue-collar and vocational occupations such as carpentry, care work, etc. The last thing any labor market policymaker would want is to accentuate the already critical skill gap in this area. Or create an even tighter labor market for certain professions, say, IT professionals [1]. Similarly, education providers seeking to align their curricula with market demand need reliable data so as not to amplify skill gaps instead of alleviating them. And yet, a growing number of PES are relying on this often shaky data for decision making and ALMP design.
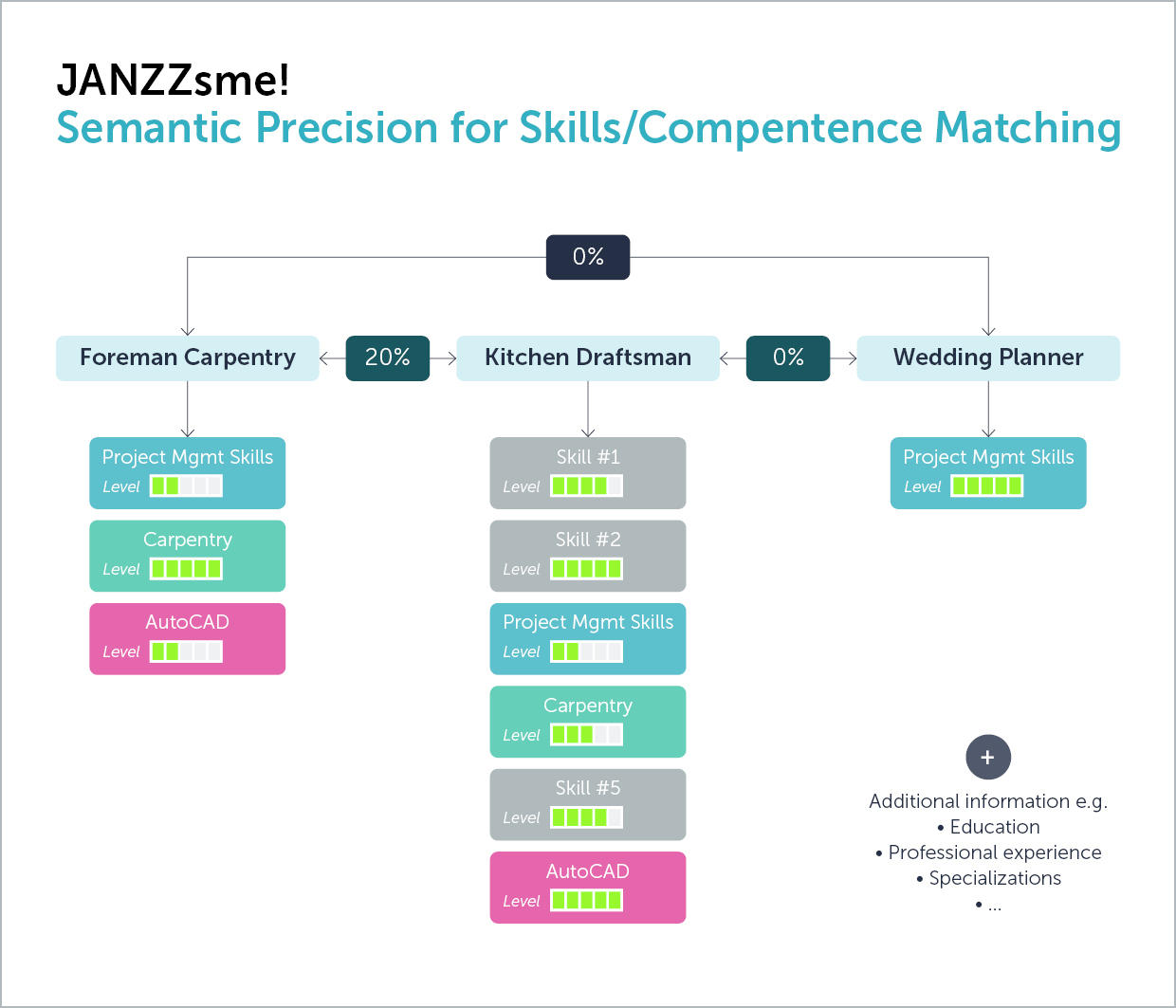
For instance, there are several projects that aim to gather and analyze all available OJA from all possible sources in a given labor market and use these aggregated data to make recommendations including forecasts of future employability and skills demand. But the skills are typically processed and presented without any semantic context, which can be extremely misleading.
Challenges of OJA data
In 2018, the European statistical system’s ESSnet Big Data project issued a report [2] on the feasibility of using OJA data for official statistics. Their conclusion was: «the quality issues are such that it is not clear if these data could be integrated in a way that would enable them to meet the standards expected of official statistics.»
Let us take a look at some of the basic challenges of OJA data.
- Incomplete and biased: Not all job vacancies are advertised online. A significant proportion of positions are filled without being advertised at all (some say around 20%, others claim up to 85% of vacancies). Of those that are advertised, not all are posted online. CEDEFOP reported that in 2017 the share of vacancies published online in EU countries varies substantially, ranging from almost 100% in Estonia, Finland and Sweden down to under 50% in Denmark, Greece, and Romania. [3] In addition, some types of jobs are more likely to be advertised online than others. And large companies or those with a duty to publish vacancies are typically statistically overrepresented while small businesses, who often prefer other channels such as print media, word of mouth, or signs in shop windows, are underrepresented. Another relevant point is that certain markets are so dried out that advertising vacancies is just not worthwhile, and specialized headhunters are used instead. In summary, this means that OJA data not only fail to capture many job vacancies, but are also not representative of the overall job market. [4]
- Duplicates: In most countries, there is no single source of OJA data. Each country has numerous online job portals, some of which publish only original ads, others that republish ads from other sources, hybrid versions, specialized sites for certain sectors or career levels, etc. So, to ensure adequate coverage, OJA data generally need to be obtained from multiple sources. This inevitably leads to many duplicates, which must be dealt with effectively in order to reliably measure labor market trends in the real world. For instance, in a 2016 project the UK national statistics institute (NSI) reported duplicate percentages of 8-22% depending on the portal, and an overall duplication rate of 10%. [5] In the ESSnet Big Data project, the Swedish NSI identified 4-38% duplicates per portal and 10% in the merged data set [6].
- Inconsistent level of detail: Certain job postings provide much more explicit information on required skills than others, for instance depending on the sector (e.g., technical/IT) or country (e.g., due to legislation or cultural habits). Moreover, implicit information is recorded only to a limited extent and is statistically underrepresented, despite its high relevance. One reason for this is that US data providers often fail to recognize how uniquely detailed OJA are in the US, thus assuming that this is true everywhere and basing their methods on this assumption. However, this is far from correct. For instance, a job description like the one below, which is fairly typical in the US, will often be condensed to «carry out all painting work in the areas of maintenance, conversions and renovations; compliance with safety and quality regulations; minimum three years of experience or apprenticeship» in European countries. Moreover, in job ads like this, many of the required skills must be derived from the listed tasks or responsibilities. This shows just how important it is to extract implicit information.

So, the question is, can these issues be dealt with in a way that can nonetheless generate meaningful data?
The answer: sort of. Limitations on representativeness can be addressed using various approaches. There is no one-size-fits-all solution, but depending on the available data and the specific labor market, statistically weighting the data according to the industry structure derived from labor force surveys could be promising; as could comparing findings from several data sources to perform robustness checks, or simply focusing on those segments of the market with less problematic coverage bias. [7]
Deduplication issues can be solved technically to a certain extent, and there is a lot of ongoing research in this area. Essentially, most methods entail matching common fields, comparing text content and then calculating a similarity metric to determine the likelihood that two job postings are duplicates. Some job search aggregators also attempt to remove duplicates themselves – with variable success. Identifying duplicates is fairly straightforward when OJAs contain backlinks to an original ad as these links will be identical. On the other hand, job ads that have been posted on multiple job boards pose more of a challenge. Thus, ideally, multiple robust quality assurance checks should be put in place, such as manual validation over smaller data sets.
Seriously underestimated: the challenge of skills extraction
The third challenge, the level of detail, seems to be the most underestimated. OJA from the US are typically much more detailed than elsewhere. A lot of information is set out explicitly that is only implicitly available in OJA data from the UK and other countries (e.g., covered by training requirements or work experience) – or not given at all. But even within the US, this can vary greatly.

Clearly, even if we can resolve the issues concerning representativeness and duplicates, simply recording the explicit data will still result in highly unreliable nowcasts or forecasts. Instead, both the explicit and implicit data need to be extracted – together with their context. To reduce the distortions in the collected data, we need to map them accurately and semantically. This can be done with an extensive knowledge representation that includes not only skills or jobs but also education, work experiences, certifications, and more, as well as required levels and the complex relations between the various entities. In this way, we can capture more implicit skills hidden in stipulations about education, qualifications, and experience. In addition, the higher granularity of OJA data is only truly useful if the extracted skills are not clustered or generalized too much in subsequent processing, e.g., into terms like “project management”, “digital skills” or “healthcare” (see our previous post), due to working with overly simplified classifications or taxonomies instead of leveraging comprehensive ontologies with a high level of detail.
And then of course, there is the question of how to analyze the data. We will delve deeper into this in the next post, but for now, this much can be said: Even if we are able to set up the perfect system for extracting all relevant data from OJAs (and candidate profiles for that matter), we are still faced with the challenge of interpreting results – or even just asking the right questions. When it comes to labor market analyses, nowcasting and forecasting, e.g., of skills demand, combining OJA data with external data such as from surveys by NSI promises more robust results as the OJA data can be cross-checked and thus better calibrated, weighted and stratified. However, relevant and timely external data is extremely rare. And we might possibly be facing another issue. It is much easier and cheaper to up- or reskill jobseekers with, say, an online SEO course than with vocational or technical training in MIG/MAG welding. So maybe, just maybe, some of us are not that interested in the true skills demand…
[1] According to the 2020 Manpower Group survey, IT positions are high on the list of hardest-to-fill positions in the US, but not everywhere else. In some countries, including developed ones such as UK and Switzerland, IT professionals are not on the top 10 list at all.
[2] https://ec.europa.eu/eurostat/cros/sites/crosportal/files/SGA2_WP1_Deliverable_2_2_main_report_with_annexes_final.pdf
[3] The feasibility of using big data in anticipating and matching skills needs, Section 1.1, ILO, 2020 https://www.ilo.org/wcmsp5/groups/public/—ed_emp/—emp_ent/documents/publication/wcms_759330.pdf
[4] The ESSnet Big Data project also investigated coverage, for the detailed results see Annexes C and G in the 2018 report.
[5] https://ec.europa.eu/eurostat/cros/content/WP1_Sprint_2016_07_28-29_Virtual_Notes_en
[6] https://ec.europa.eu/eurostat/cros/sites/crosportal/files/WP1_Deliverable_1.3_Final_technical_report.pdf
[7] See for example Kureková et al.: Using online vacancies and web surveys to analyse the labour market: a methodological inquiry, IZA Journal of Labor Economics, 2015, https://izajole.springeropen.com/track/pdf/10.1186/s40172-015-0034-4.pdf