The One-Eyed leading the Blind – Part 3: Farewell, Mythical Machine.

This is the third in a series of posts on machine learning in HR tech. If you haven’t already, we recommend you read the other two posts first: part 1 and part 2.
In the last two posts, we discussed the need for domain experts in building a knowledge graph for a job matching engine as well as the problem we want to solve on a conceptual level. In this post, we’re going to delve into the challenges of building a job matching system on a more technical level. (Don’t worry, it’s not going to get too technical – or at least not for long…) We will again focus on a job matching system as an example, but the basic ideas are relevant to many different applications in HR tech.
Based on the discussion in the last post, the goal of our system is to input raw, unstructured data like resumes and job descriptions, process the data fairly and accurately to output the best matches, and explain the results truthfully. For sake of argument, let’s say we’re matching candidates to a job. We won’t discuss potential graphical elements in resumes, say skill levels or section headers, because that’s a huge challenge in and of itself (which, by the way, we’ve recently solved here at JANZZ). Instead, we’ll focus on input data in the form of text.
In the broadest sense, there are two approaches we can take:
- Perform matching right on the text data, or
- First transform the raw text data into normalized tabular data and then perform matching on the tabular data.
Tabular data is generally not considered avant-garde, but AI-based text processing is hugely popular (pretty much anyone not living under a rock has heard of NLP, GPT-3 or conversational AI). This may be at least part of why the first approach is by far the most common in HR tech: You get to throw out all those fancy words when marketing your products – NLP, deep learning, cutting-edge, yadda yadda. So let’s try and build a matching engine like this.
If you want to perform matching on text data, your system has to deal with actual words. Since digital systems are designed to deal with digits, this means the words have to be translated into digits in some way that is meaningful to the machine. The document text must be turned into an array, or vector, of numbers. In the simplest version, you have a dictionary of all possible words in your resume/job description universe, and a formula that assigns a number to each word in the dictionary based on the document at hand. This could be, for instance, a count of how often the word appears in the document, multiplied with some weight based on relevance or other criteria. So for each document, you get an array (vector) with as many slots (components) as there are words in your dictionary, filled with numbers according to that formula. If, in addition, you want to somehow encode context to better capture the meaning of these words, you might extend your dictionary to include certain sequences of words as well.
Whether you include context or not, a significant challenge of this technique is the sheer number of potential words or phrases that candidates and recruiters can put in their resumes and job descriptions. For instance, there are tens of thousands of standardized skills in collections like ESCO or LinkedIn. And real-life people don’t just use standardized terms. So just for skills, you’ll end up with millions of different expressions, many of which are related to each other to varying degrees. And because the number of expressions corresponds to the number of components in the vectors representing the documents, you end up with huge vectors for each document, causing significant computational challenges down the road. So somehow or other, this complexity needs to be reduced, i.e., we want to condense the information contained in the documents into smaller vectors – but without losing the underlying semantics. This inevitably leads to embeddings; where complex models based on deep neural networks typically perform significantly better than simple models. In this approach, the model decides, based on its training data, how to transform candidate and job profiles into much smaller vectors that live a vector space (think points with coordinates labeling their positions in a three-dimensional space) in such a way that vectors representing similar profiles are close to each other. If you then feed it new profiles, it can embed them in the same way and just look for the ones that are closest together (nearest neighbors). Sounds fairly straightforward, right? Well, it’s not.
For our purposes, one of the key issues with embeddings (and, by the way, with neural networks in general) is their lack of interpretability: the components of the vectors no longer individually correspond to semantic concepts or other directly interpretable distinctions. There have been multiple attempts in the scientific community to address this issue. So far, however, the proposed approaches have proven computationally impractical, resulted in poor performance, or shown very little improvement in interpretability. This means that there is no way of knowing for certain which criteria the system used to determine similarity between two profiles. Instead, we have to make do with post-hoc explanations using additional methods. But all these methods do is perform yet more statistics to determine the most likely explanations for the system’s behavior. And, as studies have determined, different explanation methods often disagree in terms of the resulting explanations, showing that they rarely produce truthful insight into the decisions made by the system. In fact, to quote one study: “The higher the model complexity, the more difficult it may be for different explanation methods to generate the true explanation and the more likely it may be for different explanation methods to generate differently false explanations, leading to stronger disagreement among explanation methods.” This could become a serious liability concern in the not-too-distant future. Or this phenomenon could be exploited to avoid liability. As it turns out, explanation techniques can easily be abused for fair washing, ethics washing, white box washing, or whatever you want to call it. For instance, this study demonstrates that decisions taken by an unfair black-box model can be systematically rationalized through an explanation tool that provides seemingly fair explanations with high fidelity to the black-box model.
On top of that, no matter what modeling method you use, and what explanation method: If you ask why a particular output corresponds to a particular input, the answer depends not only on the mechanics of the particular method, but also very significantly on the distribution of the training set. Which leads us to the next point.
We are asking this system to understand similarity of expressions (e.g. synonyms, near-synonyms), of the underlying concepts (e.g. similar skills, job titles, certifications, and so on), and of the complete profiles. On the level of expressions and concepts, we can certainly use our knowledge graph, which – after reading the first post in this series – we built and curate with domain experts. But for the actual matching, our ML model needs vast amounts of high-quality data to learn the similarities between profiles. Of course, when you hear the vast numbers of resumes or job postings certain providers claim to process, you immediately think there’s ample job-related big data out there to feed into our system. But that’s like saying there are countless images on the internet so you can easily train a system to recognize images of, well, everything. In image recognition, it is well understood that a model that recognizes images of poodles cannot easily be retrained to recognize Venezuelan Poodle moths – even though they do share some similarities…

The same is true for job or skill similarity. Just like the universe of images, the labor market domain is very heterogeneous. What makes two jobs similar in one case does not necessarily transfer to another. Instead, you need a large amount of data covering similarities in each one of many different areas including niche careers such as ocularists and hippotherapists (if you don’t know what these people do, that’s exactly the point). Because this niche data simply doesn’t exist in the quantity this system needs, we have to find a way to work around this issue. And there are, of course, techniques to deal with small datasets, but they are not easy to implement, and maintaining high quality of data to achieve good results is challenging with any of the current techniques. This is a key reason most job matching systems on the market perform more or less ok when matching software engineers to roles, but fail miserably for occupations with less online coverage, or where the coverage is asymmetric between job postings and online candidate profiles, like blue collar workers in waste management.
In addition, labor markets continuously evolve, even dramatic shifts can happen very quickly on multiple levels, new occupations, new employers, new educations emerge all the time, certain skills become irrelevant, other become more important. These dynamics can cause models to go stale quickly, requiring frequent retraining to maintain performance. This requires not only an endless supply of fresh training data, with all the challenges that entails, and countless hours of highly paid work, but, due to the GPU-hungry processes involved, also comes with a significant carbon footprint.
We set out to build a system that produces fair and accurate results with truthful explanations. But so far, we can’t be sure our system can provide truthful explanations, or that we can continuously feed our hungry system with enough high-quality training data to produce fair and accurate results in all professional fields—at least not without burning through the budget and the planet at a painfully high rate. And then Molnar, author of the highly influential book Interpretable Machine Learning, tells you that in fact, when dealing with small datasets, interpretable models with good assumptions often perform better than black-box models.
Maybe we should try a different approach after all.
Tabular data may not sound very exciting, but it comes with an interesting feature: For tabular data, deep learning models generally do not perform better than simple models.[1] In other words, there are simple models that are at least as accurate as your highly complex, state-of-the-art model. And, unlike a complex model, any one of these simple models can be designed to be interpretable. Of course, we still have the challenge of obtaining and preparing high-quality training data and securing the right people for quality assurance, localization, and so on. The challenges are very similar to those for knowledge graphs discussed in the first post of this series. But at least we can eliminate the issue of unreliable explanations and easily identify and correct any bias. We could, by the way, also just build similarity into our human-curated knowledge graph and skip ML in the matching step altogether. Either way, this leaves us with the – by no means simple – problem of parsing and normalizing raw text data.
Without getting too deep into the weeds, parsing and normalizing text data is a language-based problem that requires a large amount of very careful training and a knowledge graph. With the right combination of natural language processing/deep learning models we can certainly build a powerful parser – provided we can feed it with carefully curated gold-standard training sets.
As for normalization, we need it, and we need high performance: Without good normalization, our matching system will produce less accurate results. For instance, by weeding out good candidates for using terms that even only slightly differ from those in the job description, or by giving higher weight to skills that are written in several different ways within both of the documents. Here’s a real-life example of failed normalization:
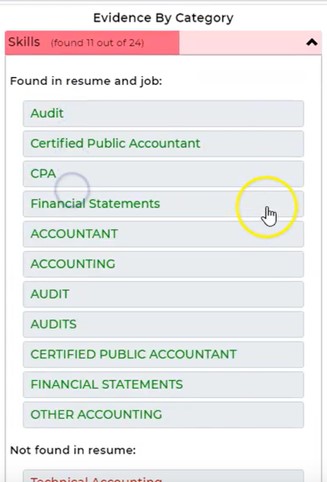
Because the terms “Audit”, “AUDIT” and “AUDITS” are not recognized as the same concept, the weight of this single skill is tripled. In fact, the eleven skills the system claims to have recognized in both the job description and the resume actually only comprise three to four distinct concepts. And even if we made our parser case-insensitive (which, clearly, any decent parser should be), it would not be able to equate the expressions “Certified Public Accountant” and “CPA”. If we now had another candidate who had ten distinct skills matching the job description, that person may rank lower than this candidate. (As a side note, “financial statements” is not a skill. Is this someone who can prepare financial statements? Or audit them? Maybe just read them?)
Of course, if we want to perform normalization, we need something to normalize the terms against. Which is where our knowledge graph comes in. And the better and more extensive the knowledge graph is, the better the normalization. By the way, the vendor from this example claims to provide the most accurate parser in the industry. So much for marketing claims. They also claim to perform knowledge graph-based normalization. Then again, their knowledge graph is built with ML…
So, what have we learnt? When it comes to job matching, complex approaches using the latest ML techniques are not necessarily a good choice. They may be more exciting in terms of marketing, but given the explainability issues, data challenges and – most importantly – the poor results, they are by no means worth the time, money or effort required. A much more promising approach may be to keep the matching step simple and instead focus on accurately processing the input data. For instance, by building a world-class parser using deep tech and gold-standard training sets – i.e., annotated by people who understand the content and context of the data – combined with a knowledge graph built and curated by people who – you guessed it – understand the content and context of the knowledge modeled by the graph. So you still get to play with cutting-edge machine learning and data science tech. But you also get to broaden your horizon and work with people who know about something other than data science and machine learning. And it will lead to better results. Not just “statistically significant single-digit percentage improvements” because, let’s be honest, single digit improvements on appalling is still far from great.
As 2022 comes to a close, maybe it’s time to reflect on how much money and effort has been spent and how little has been achieved since we first started out. And ask yourself if the time has finally come to bid farewell to the mythical beast you have been pursuing for so long.
May 2023 bring you new beginnings.
[1] See, for example: Rudin, Cynthia, Chaofan Chen, Zhi Chen, Haiyang Huang, Lesia Semenova, and Chudi Zhong. “Interpretable machine learning: Fundamental principles and 10 grand challenges.” Statist. Surv. 16 (2022): 1-85 and Shwartz-Ziv, Ravid, and Amitai Armon. “Tabular data: Deep learning is not all you need.” Information Fusion 81 (2022): 84-90.
