JANZZparser!
The first port of call for unstructured HR data.
On the web you will find a lot of creative information from various tech providers and software companies about the capabilities and outstanding performance of their job or CV / resume parser. Each provider claims their solution is the best and the fastest, makes the least mistakes and deviations and is available in the most languages. Usually, these claims are even underlined by some impressive results and bold percentages. A word of advice: do not believe everything you read. Instead, convince yourself of the real, far-reaching possibilities of JANZZparser! by watching our demo. Seeing is believing…
Ultra-safe multilingual semantic job and CV / resume parser
JANZZ.technology offers both a job advertisement parser and a CV / resume parser as a fully GDPR/CCPA-compliant, ultra-safe ISO 27001 certified private cloud service – the perfect tool for anyone who needs to organize large amounts of unstructured and potentially highly sensitive occupation‑related data. Using semantic technology and following the OECD Principles on Artificial Intelligence, JANZZparser! extracts all relevant information from data such as job advertisements or CVs / resumes. It then sorts the extracted information into relevant categories, providing smart data for search and matching, reporting and analytics, and other useful processing.
JANZZparser! also recognizes information that is often not explicitly named in the text, such as language skills. Our job parser and CV / resume parser support 60+ languages and dialects and can recognize every common job advertisement, CV and resume format, including doc, docx, pdf, html, xml, rtf, csv, txt and more. JANZZparser! can successfully identify information within your documents from over 50 categories including:
| In job advertisements | ||
|---|---|---|
| Occupation | Education | Working conditions |
| Function | Experience | Place of work (GPE) |
| Specialization | Level (skill/experience) | Contract type |
| Supervisor | Languages | Salary |
| Company | Authorizations / Certifications | Social tags |
| Skills | Industries | Number of vacancies |
| Soft skills | Availability | … |
| In CVs / resumes | ||
|---|---|---|
| Occupation | Authorizations / Certifications | First / Last name |
| Function | Schools / training companies | Contact information |
| Specialization | Places of work (GPE) | Social media profiles |
| Companies | Dates worked | References |
| Skills | Titles or degrees | Social tags |
| Soft skills | Grade point average (GPA) | Availability |
| Language skills | Portfolio | Desired salary |
| Education | Publications | Career goals |
| Experience (work / industry / role) | Achievements | Date / Place of birth |
| Level (skills / experience) | Memberships | … |
Our job parser and CV / resume parser can handle multiple languages even within a single document. Each language is backed by carefully trained language-specific supervised deep learning models. We currently cover the following:
- Higher recall/precision: Chinese (traditional, simplified), Dutch, English, French, German (3 localized versions: Germany, Switzerland, Austria), Italian, Japanese, Korean, Norwegian (Bokmål, Nynorsk), Portuguese (Portugal, Brazil), Spanish (Castilian, several Latin American variants), and Vietnamese
- Lower recall/precision: Arabic, Azerbaijani, Basque, Bengali, Bulgarian, Catalan, Croatian, Czech, Danish, Estonian, Finnish, Galician, Greek, Hausa, Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Khmer, Latvian, Lithuanian, Malay, Maltese, Maori, Nepali, Northern Sami, Oromo, Pashto, Persian/Farsi, Polish, Romanian, Russian, Serbian, Slovak, Slovenian, Swahili, Swedish, Tagalog, Tamil, Thai, Tibetan, Turkish, Ukrainian, Urdu, Yoruba, etc.
JANZZon!, the key to high performance and smart data
At the heart of our job parser and CV / resume parser is our unique job and skills ontology JANZZon!. This extensive hand-curated knowledge representation is the perfect basis for precise and accurate parsing. The knowledge of professions and skills modeled in the world’s largest multilingual ontology of occupation-related data allows for textual identification and semantic parsing of all labor market related terms, driving astonishing results.
The diagram illustrates the architecture of JANZZparser!, which combines JANZZon! with cutting-edge deep learning models.
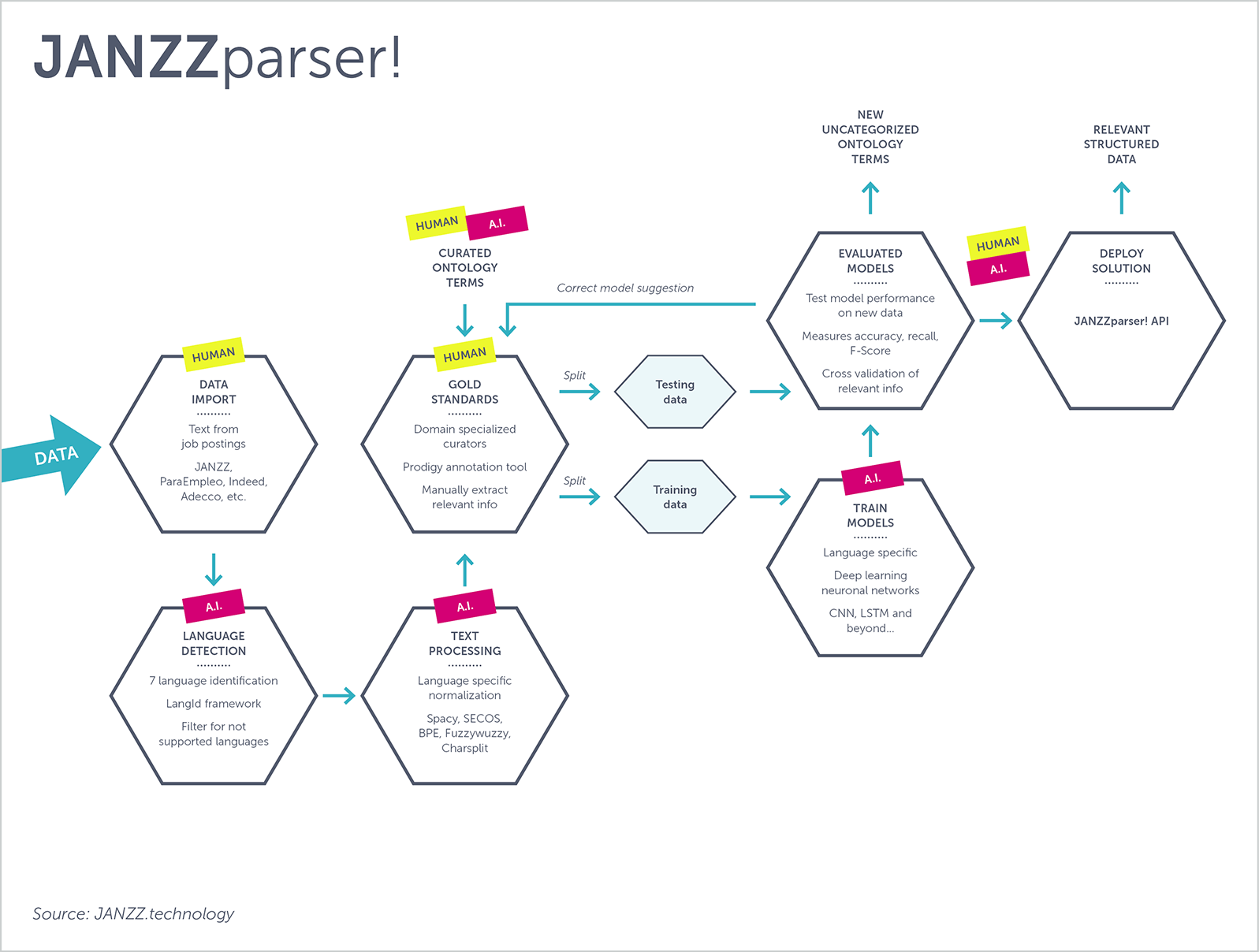
Why JANZZparser! is the ideal tool for you:
Semantic capability powered by JANZZon!
JANZZon! the world’s largest multilingual ontology of occupation-related data, serves as the extensive knowledge base, which drives precise and accurate parsing results by turning your big data into valuable smart data.
Multilingual parsing
More than 60 supported languages and dialects, each backed by trained language-specific deep learning models and automatically detected in your documents. Our job parser and CV / resume parser can even handle multiple languages in a single document.
Robustness
We offer a robust, cost effective, efficient, and reliable way to organize your unstructured occupation data, via JANZZjobsAPI.
Accuracy
Driven by the semantic engine, JANZZparser! transforms job advertisements and CVs / resumes from any common format into meaningful data with astonishing accuracy and granularity. Additionally, our data analysts make corrections and progress on a daily basis, using real-time data.
Continuously self-improving
Our customers include global enterprises and public employment services which constantly use our services on a large scale. Our machine learning algorithm uses the huge amounts of user data for supervised self-improvement.
Security
Our services are fully compliant with GDPR/CCPA and ISO27001. Unlike public clouds, such as AWS, Google or Azure, the private cloud hosted by JANZZ.technology secures your data and privacy at the highest available level.
Easy integration
Our job parser and CV / resume parser is easily integrable with the most frequently used recruitment CRMs, ATS and job portals on the market.