Savez-vous comment construire une maison ? Si ce n’est pas le cas, vous devriez peut-être envisager de l’apprendre. Effectivement, en 2030, il y a de fortes chances qu’il y ait une grave pénurie de main-d’œuvre dans la construction et c’est donc le moment idéal pour acquérir des compétences telles que l’installation de câbles électriques, la menuiserie, la maçonnerie, les systèmes d’étanchéité et la plomberie.
Selon le rapport 2020 de l’Association suisse du bâtiment (Schweizerischer Baumeisterverband)[1], l’industrie suisse de la construction est confrontée à des problèmes considérables : de moins en moins de jeunes sont prêts à apprendre un métier lié à la construction et, par ailleurs, un grand nombre des travailleurs qualifiés actuels sont sur le point de prendre leur retraite. Par rapport à 2010, 40% moins de jeunes ont commencé un apprentissage de maçon en 2019. Cela aura un impact critique sur l’ensemble du secteur car la majorité des contremaîtres, superviseurs et directeurs de la construction sont recrutés dans le pool des maçons. D’autre part, les personnes âgées de plus de 50 ans représentent aujourd’hui 36 % du secteur principal de la construction. Le résultat de cette combinaison semble prédire un futur alarmant.
Ces dernières années, le niveau des qualifications professionnelles sur les chantiers de construction a fortement augmenté en raison de la numérisation, laissant le travailleur typique non qualifié confronté à une baisse de la demande. De plus, cela crée des différences considérables entre l’offre et la demande des compétences de main-d’œuvre dans ce secteur. Toutefois, les facteurs de la pénurie des qualifications sont beaucoup plus complexes.

Tendances démographiques
La baisse des taux de natalité et l’augmentation de l’espérance de vie sont les deux tendances démographiques clés en Suisse et dans l’Union européenne. La combinaison de la diminution de la population en âge de travailler, avec la population vieillissante, a aggravé la situation du marché du travail. Selon les données d’Eurostat [2], la part de la population en âge de travailler par rapport à la population totale de l’UE a diminué de plus de 2 % entre 2010 et 2018 et l’âge médian a augmenté de près de trois ans pour atteindre 43,1 ans au cours de la même période.
En outre, l’impact des nombreux employés qui s’apprêtent à partir à la retraite n’a pas encore été pleinement pris en compte 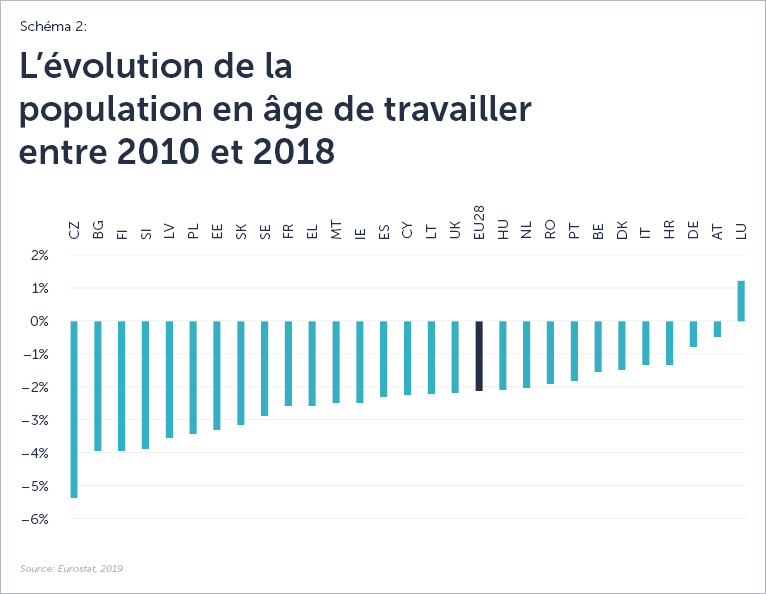 dans les statistiques. Selon une étude du Crédit Suisse [3], environ 1,1 million de personnes atteindront l’âge de la retraite dans les dix prochaines années et la jeune génération ne sera pas en mesure de pourvoir les nombreux emplois hautement qualifiés laissés vacants par la génération du baby-boom de l’après-guerre. Des études menées dans d’autres pays d’Europe centrale révèlent des attentes similaires concernant l’impact des baby-boomers sur leur marché du travail.
dans les statistiques. Selon une étude du Crédit Suisse [3], environ 1,1 million de personnes atteindront l’âge de la retraite dans les dix prochaines années et la jeune génération ne sera pas en mesure de pourvoir les nombreux emplois hautement qualifiés laissés vacants par la génération du baby-boom de l’après-guerre. Des études menées dans d’autres pays d’Europe centrale révèlent des attentes similaires concernant l’impact des baby-boomers sur leur marché du travail.
Cependant, de nombreux rapports ont indiqué une pénurie de travailleurs qualifiés dans le secteur de la construction pour les pays qui n’ont pas cette forme démographique, comme l’Afrique du Sud et l’Inde. Apparemment, un facteur plus général est à l’origine de la pénurie de compétences dans le secteur de la construction au niveau international.
Image négative
De nombreuses études menées dans le monde entier montrent que l’industrie de la construction a une image négative, en particulier auprès des jeunes. Par exemple, dans une étude menée dans un lycée par le « National Business Employment Weekly » en Afrique du Sud, les carrières dans la construction sont placées au rang numéro 247 sur les 250 carrières les moins attrayantes [4]. Les données du CITB en 2013 [5] ont montré qu’au Royaume-Uni, l’attrait global de l’industrie de la construction comme option de carrière était tombé à seulement 4,2 sur 10 chez les adolescents âgés de 14 à 19 ans, et l’« Union of Construction, Allied Trades and Technicians » (UCATT) a également fait état d’une baisse de 14,6 % du nombre d’apprentis dans la construction en 2013. Un autre sondage réalisé en 2017 a confirmé ceci une nouvelle fois. Dans une enquête de 2017, on a remarqué qu’aux États-Unis, seuls 3 % des jeunes âgés de 18 à 25 ans souhaitaient travailler dans les métiers de la construction [6].
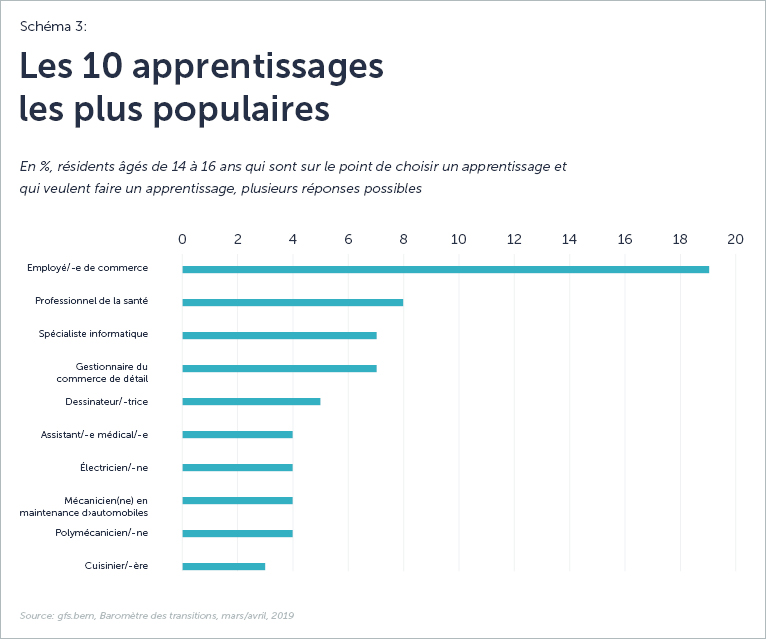 Malgré les perspectives de carrière prometteuses dans un domaine en demande, les jeunes ne semblent pas pouvoir se défaire de la mauvaise image du secteur, comme par exemple : les bas salaires et la sécurité de l’emploi, les problèmes de santé et de sécurité, la mauvaise qualité du travail et les conditions de travail difficiles. Ceux-ci sont les aspects que les jeunes associent le plus souvent aux emplois dans la construction et qui les dissuadent de poursuivre une carrière dans ce secteur. Par ailleurs, l’essor de la numérisation alimente la crainte que les emplois à l’avenir dans la construction puissent devenir victimes de l’automatisation.
Malgré les perspectives de carrière prometteuses dans un domaine en demande, les jeunes ne semblent pas pouvoir se défaire de la mauvaise image du secteur, comme par exemple : les bas salaires et la sécurité de l’emploi, les problèmes de santé et de sécurité, la mauvaise qualité du travail et les conditions de travail difficiles. Ceux-ci sont les aspects que les jeunes associent le plus souvent aux emplois dans la construction et qui les dissuadent de poursuivre une carrière dans ce secteur. Par ailleurs, l’essor de la numérisation alimente la crainte que les emplois à l’avenir dans la construction puissent devenir victimes de l’automatisation.
En effet, certains métiers de la construction ont un potentiel d’automatisation plus élevé, comme les opérateurs d’engins de chantiers, mais techniquement il n’est pas toujours possible d’effectuer certaines tâches avec des robots. Même le travail physique, dont beaucoup pensent qu’il est le plus susceptible d’être automatisé, serait peut-être trop difficile pour les robots, en particulier les tâches physiques dans des environnements imprévisibles et changeants.
Lorsque l’on fait référence aux professions de la construction, les gens ne pensent généralement qu’aux activités sur site. On néglige souvent les professions liées à des sous-secteurs tels que les activités d’architecture ou d’ingénierie, l’immobilier et les achats qui jouissent d’un statut social plus élevé et pourraient sembler plus attrayantes pour les hommes comme pour les femmes.
Un intérêt croissant pour la voie académique
Dans le système de formation par alternance, pratiqué notamment en Allemagne, en Autriche et en Suisse (« DACH »), la plupart des parcours professionnels dans le secteur de la construction commencent par une formation professionnelle et un apprentissage. Tradition de longue date dans ces pays, ce système a été bien reçu par la société en général. Mais dernièrement, l’intérêt croissant pour les diplômes universitaires a posé un défi direct aux professions du secteur de la construction et aux autres métiers spécialisés.
Au moment où les diplômés universitaires sont confrontés à un choix de carrière, il est déjà trop tard pour les attirer sur le chantier. Les recherches montrent que le choix du moment est essentiel pour parvenir à susciter l’intérêt pour les professions de la construction, et le taux de réussite est plus élevé si on commence à enthousiasmer les écoliers au niveau primaire. Afin de rendre le milieu de la construction plus attrayant, il faudra déployer des efforts conjoints pour pouvoir apporter des changements fondamentaux au système éducatif et favoriser une collaboration plus étroite entre l’industrie et les établissements d’enseignement.
La libre circulation des travailleurs qualifiés est indispensable
C’est certainement une stratégie prometteuse pour le long terme et les futures générations de travailleurs. À court et moyen terme, cependant, les économies nationales – en particulier dans les pays industrialisés et en voie d’industrialisation rapide – dépendront fortement des flux d’ouvriers qualifiés du monde entier pour atténuer la pénurie de main-d’œuvre. En effet, comme le souligne l’« OIT » [7], les migrants sont une source vitale de compétences et de force de travail pour les secteurs tels que la construction. Il est évident que l’industrie de la construction exige des équipes flexibles possédant des compétences variées, et est donc souvent extrêmement dépendante des travailleurs migrants compte tenu de leur mobilité et de leur flexibilité. Par conséquent, les solutions contribuant à la libre circulation des personnes vont rapidement faire l’objet d’une demande croissante. Toutefois, pour assurer une véritable libre circulation des travailleurs, il faut aborder dès le départ une question importante : la reconnaissance des qualifications entre les différents pays et même, les différentes régions d’une nation.
Les défis de la reconnaissance des compétences
Dans l’UE, la « directive sur les qualifications professionnelles » (DQP), le « cadre européen des certifications » (CEC) et le « système européen de crédits d’apprentissages pour l’enseignement et la formation professionnels » (ECVET) sont les principaux instruments de reconnaissance des qualifications professionnelles et académiques pour soutenir la mobilité des travailleurs à travers l’Europe. Cependant, malgré des efforts importants tels que le lancement du système européen de classification des qualifications, compétences, qualifications et professions (ESCO), la reconnaissance et l’adéquation des compétences entre les pays membres restent très décevantes, et cela, sans même parler de la situation internationale. La comparaison des compétences au-delà des frontières pose deux défis importants. Premièrement, de nombreux pays ont leurs propres systèmes de classification ou taxonomies qui doivent être mis en correspondance dans un système transnational, et tous ne l’ont pas encore fait. Deuxièmement, il n’est pas si facile de traduire toutes les compétences et qualifications. Par exemple, un charpentier qui a suivi un apprentissage de 18 mois au Royaume-Uni aura un ensemble de compétences différent de celui d’un charpentier ayant suivi un apprentissage de trois ans en Autriche, même si tous les deux ont suivi une formation standardisée pour le même métier spécialisé.
C’est pour ces différentes raisons que de plus en plus d’investissements et d’espoir sont placés dans les ontologies et les technologies sémantiques comme solution pour surmonter ces défis. Actuellement, l’ontologie de JANZZ est la plus grande représentation encyclopédique multilingue des connaissances dans le domaine des données sur les professions. Non seulement elle est capable de traduire les nombreuses variations linguistiques du jargon professionnel en un vocabulaire commun, mais grâce au traitement par expertise humaine, elle peut véritablement comparer les différences et les similitudes en matière de formations et de qualifications au-delà les frontières et des divisions linguistiques – apportant ainsi une contribution significative à la libre circulation des travailleurs qualifiés.
Contactez-nous dès maintenant pour comprendre comment l’ontologie de JANZZ peut vous aider dans la reconnaissance de la formation et des qualifications de votre main-d’œuvre.
[1] Zahlen und Fakten 2020, Schweizerischer Baumeisterverband SBV
[2] European Commission, Improving the human capital basis, Analytical Report (March 2020)
[3] Credit Suisse, Fear of recession exaggerated (September 2019)
[4] Makhene, D., Thwala, W.: Skilled labour shortages in construction contractors: a literature review
[5] UK Construction: An Economic Analysis of the Sector (July 2013)
[6] Young Adults & the Construction Trades, NAHB Economics and Housing Policy Group
[7] Buckley et al.: Migrant work and employment in the construction sector, Geneva: ILO, 2016






{kind=link}