A palavra “ontologia” pode ser abstrata para muitas pessoas. A sua origem vem de um sonho de Tim Berners-Lee de inventar a World Wide Web. Este sonho incluía que a Web fosse capaz de definir a chamada “web semântica”, analisando todos os dados da rede, incluindo conteúdo, links e transações entre computadores e pessoas. Na web semântica, o Resource Description Framework (RDF) e Web Ontology Language (OWL) foram estabelecidos como formatos padrão para compartilhar e integrar dados e conhecimentos, este último na forma de ricos esquemas conceituais chamados ontologias [1.] Neste artigo, vamos usar a palavra ontologia como uma definição de metodologia de trabalho, no entanto, vale ressaltar que, no mundo atual das tecnologias de informação e comunicação, o termo “gráfico de conhecimento” é amplamente utilizado como sinônimo de ontologia.
Porque uma ontologia é importante
Falando em Inteligência Artificial (IA), os termos “Big Data”, “aprendizagem automática” e “aprendizagem profunda” estão lentamente substituindo o uso do termo “IA”. No entanto, para citar Adrian Bowles: “não há inteligência artificial sem a representação do conhecimento”. Em outras palavras, a IA requer elementos de engenharia do conhecimento, arquitetura da informação e uma quantidade significativa de trabalho humano para realizar seu “trabalho neural mágico”. Alexander Wissner-Gross argumenta que talvez a coisa mais importante seja reconhecer que são os conjuntos de dados inteligentes e não os algoritmos que provavelmente serão o fator principal limitante no desenvolvimento da inteligência artificial no nível humano.
“Não há inteligência artificial sem a representação do conhecimento.”
Uma ontologia é uma representação estruturada e formal do conhecimento relacionado a uma determinada área. Isso é necessário porque, ao contrário dos humanos, a IA não pode ser diretamente baseada em noções humanas pré-estabelecidas sobre o uso correto de um termo. O que uma ontologia pode fazer, entretanto, é “aprender” sobre o significado semântico de um termo através das ligações entre os conceitos de seu sistema. Já existem ontologias poderosas em campos específicos, como a Ontologia da Indústria Financeira Empresarial (FIBO), bem como numerosas ontologias para a área da saúde, geografia ou setor de emprego.
Outra parte importante da IA é o raciocínio semântico. Além de identificar transações potencialmente fraudulentas, determinar a intenção dos usuários baseando-se no histórico do navegador e fazendo recomendações de produtos, a IA também pode fazer o seguinte: executar tarefas que requerem raciocínio explícito, baseado em conhecimento geral e específico do assunto, como compreender artigos de notícias, preparar comida ou comprar um carro. Esse tipo de tarefa requer informações que não fazem parte dos dados de entrada e devem ser combinadas dinamicamente com o conhecimento. Este tipo de raciocínio informático só pode ser alcançado com ontologias e a forma como o conhecimento que elas incluem é estruturado. [2]
Taxonomia e ontologia são fundamentalmente diferentes
A ontologia é muitas vezes confundida com a taxonomia. Além do fato de que ambos termos pertencem aos campos de IA, web semântica e engenharia de sistemas, não há muito mais que os defina como sinônimos. Classificações taxonómicas como O*NET (Rede de Informação Ocupacional) e ESCO (European Skills/Competences, qualifications and Occupations) simplesmente não podem ser comparadas com ontologias. As primeiras fornecem uma abordagem muito mais simples para a classificação de conceitos, uma vez que têm uma estrutura hierárquica e utilizam apenas relações pai-filho entre termos, sem uma ligação adicional mais sofisticada. As ontologias, por outro lado, são uma forma muito mais complexa de categorização. Metaforicamente falando, uma taxonomia seria equivalente a uma árvore, enquanto uma ontologia seria para uma floresta.
Aqui um exemplo: O termo “golfe” pode aparecer em várias taxonomias. Pode estar localizado debaixo de uma árvore de ” 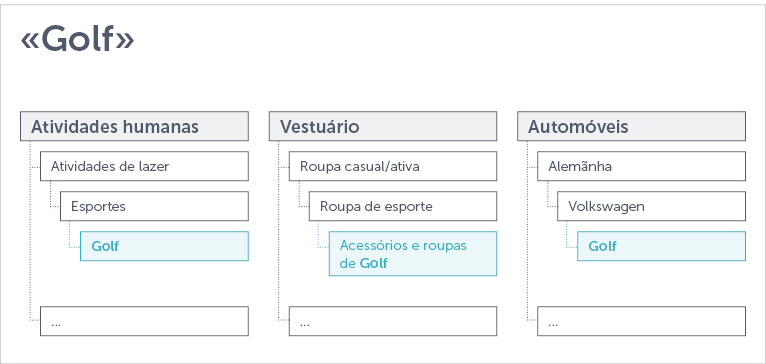 Atividades humanas” (atividades humanas -> atividades de lazer -> esportes -> golfe). Ele também pode ser encontrado em uma taxonomia relacionada com o vestuário (vestuário -> vestuário casual/activo -> vestuário desportivo -> vestuário de golfe e acessórios). Ele poderia até mesmo aparecer em algo muito diferente, por exemplo, uma taxonomia de carro (carro -> Alemanha -> VW -> Golf). Em uma ontologia, cada uma dessas taxonomias pode ser considerada como uma árvore, cujos galhos se conectam com o nó “golfe” de outros galhos, de outras árvores. [3]
Atividades humanas” (atividades humanas -> atividades de lazer -> esportes -> golfe). Ele também pode ser encontrado em uma taxonomia relacionada com o vestuário (vestuário -> vestuário casual/activo -> vestuário desportivo -> vestuário de golfe e acessórios). Ele poderia até mesmo aparecer em algo muito diferente, por exemplo, uma taxonomia de carro (carro -> Alemanha -> VW -> Golf). Em uma ontologia, cada uma dessas taxonomias pode ser considerada como uma árvore, cujos galhos se conectam com o nó “golfe” de outros galhos, de outras árvores. [3]
Explicadas de outra forma, as taxonomias representam um conjunto de tópicos, que têm uma relação cujo propósito é definir “isto é…”, enquanto as ontologias desenvolvem conexões muito mais complexas, permitindo relações que reconhecem que “isto” “tem…” e “usa…”. 4] Portanto, se voltarmos ao exemplo de classificação anterior, as taxonomias não têm a capacidade de comparar conceitos de crianças.
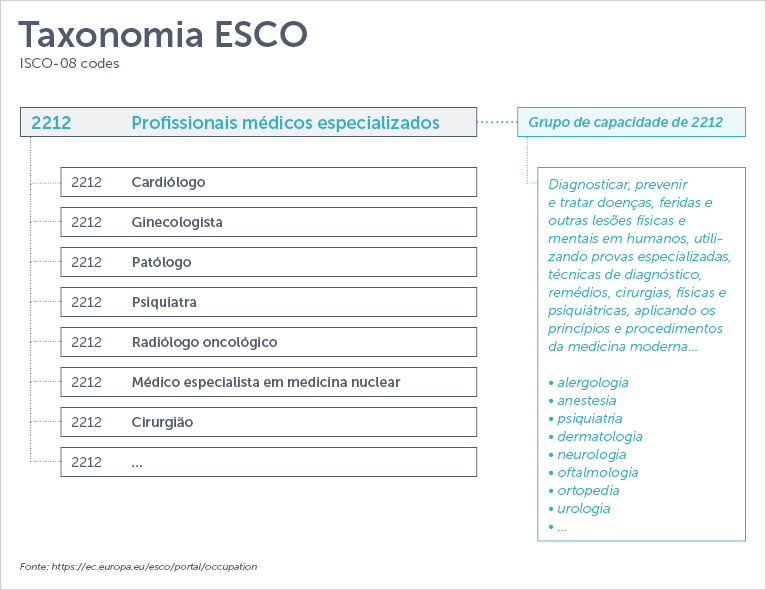 Na classificação internacional ESCO, quase todos os médicos especialistas estão agrupados sob o título: Profissionais médicos especializados. Se analisarmos este caso, torna-se evidente que um enfermeiro especializado em anestesia e um médico anestesiologista têm conhecimentos e habilidades em comum, mas não podem se aplicar ao mesmo cargo. Além disso, os conjuntos de habilidades especializadas são simplesmente agrupados em listas gerais, sem nenhum link para as ocupações especializadas correspondentes. Por que isso acontece? Uma razão é que as classificações são utilizadas principalmente para fins estatísticos. Deste ponto de vista, não há necessidade de classificar todos os médicos especialistas de acordo com as suas competências e formação específicas. Então, de acordo com as taxonomias, as especializações só podem ser reconhecidas pelo cargo e é necessário recorrer a outras fontes para entender melhor seu conteúdo específico.
Na classificação internacional ESCO, quase todos os médicos especialistas estão agrupados sob o título: Profissionais médicos especializados. Se analisarmos este caso, torna-se evidente que um enfermeiro especializado em anestesia e um médico anestesiologista têm conhecimentos e habilidades em comum, mas não podem se aplicar ao mesmo cargo. Além disso, os conjuntos de habilidades especializadas são simplesmente agrupados em listas gerais, sem nenhum link para as ocupações especializadas correspondentes. Por que isso acontece? Uma razão é que as classificações são utilizadas principalmente para fins estatísticos. Deste ponto de vista, não há necessidade de classificar todos os médicos especialistas de acordo com as suas competências e formação específicas. Então, de acordo com as taxonomias, as especializações só podem ser reconhecidas pelo cargo e é necessário recorrer a outras fontes para entender melhor seu conteúdo específico.
A construção de uma ontologia que contém: ocupações, capacidades, competências e formação, torna possível o reconhecimento automático das diferenças e semelhanças entre cargos. Por exemplo: Pediatras e neonatologistas têm empregos semelhantes, uma vez que ambos se dedicam ao cuidado da saúde dos recém-nascidos. Com a abordagem de modelagem ontológica, é possível determinar que uma pediatra tem uma percentagem muito alta de habilidades  semelhantes às de um neonatologista. No entanto, pediatras só podem assumir o trabalho do neonatologista após receber treinamento adicional. Toda esta informação pode ser representada numa ontologia, através das inter-relações entre conceitos. Estas relações excedem em muito a capacidade de uma simples taxonomia.
semelhantes às de um neonatologista. No entanto, pediatras só podem assumir o trabalho do neonatologista após receber treinamento adicional. Toda esta informação pode ser representada numa ontologia, através das inter-relações entre conceitos. Estas relações excedem em muito a capacidade de uma simples taxonomia.
Ontologias possibilitam a combinação de conjuntos de dados
Quando se trata de combinar, por exemplo, currículos com ofertas de emprego, não há melhor sistema para isso do que a utilização de uma ontologia. Muito frequentemente, formas simples de correspondência, com base em palavras-chave, ou métodos difusos de aprendizagem automática, são utilizados, o que significa que muitas semelhanças não são detectadas, portanto, não são obtidos resultados correspondentes. Elementos que levam a essa falta de resultados são, por exemplo, variações de palavras-chave introduzidas, sinônimos e frases alternativas. Para obter uma correspondência eficiente, é importante comparar a semântica (o significado subjacente) de dois elementos, em vez da redacção do texto. É aqui que as ontologias entram em jogo. Baseiam-se num modelo semântico, capaz de detectar os significados e semelhanças subjacentes entre CVs e descrições de funções.
A técnica de combinação ontológica é uma técnica fundamental que tem aplicação em muitas áreas, como a combinação de ontologias. Em domínios com regras muito complexas e interações complexas entre regras, não há substituto para ontologias. Isto é mostrado, por exemplo, quando se considera a integração de domínios muito diferentes. Suponha que existem duas ontologias separadas, uma ontologia meteorológica e uma ontologia geográfica. A criação de uma terceira ontologia que integre e tire partido do conteúdo das duas é uma proposta gerível que forneceria informações valiosas para a avaliação dos riscos de navegação ou para o domínio dos seguros. [5]
O verdadeiro valor das ontologias
O sistema semântico baseia-se em representações explícitas, e compreensíveis para o ser humano, de conceitos, relações e regras para desenvolver o conhecimento de uma determinada área. É impossível confiar unicamente nos programadores para construir tal sistema, baseado na aprendizagem automática, uma vez que eles não têm o conhecimento necessário para definir as relações entre os conceitos de cada domínio específico. Portanto, o conhecimento de uma área específica deve vir de especialistas nessa área e a integração de conhecimentos especializados em diferentes áreas é necessária (por exemplo, direitos de propriedade intelectual, dinâmica de fluidos, conserto de automóveis, cirurgia de coração aberto, ou sistemas educacionais e profissionais). Este processo é crucial para criar uma representação integral do conhecimento.
Para a ontologia multilingue da JANZZ, as capacidades são um ponto-chave. Em muitos casos, a tradução literal de um conceito para muitas línguas não é possível, no entanto, porque a Suíça é um país pequeno e multicultural, todos os nossos curadores de ontologia são fluentes em pelo menos duas línguas, e alguns até mais de quatro (incluindo chinês e árabe). Isto dá-nos uma grande vantagem, o que nos permite garantir a qualidade e consistência dos conteúdos em diferentes idiomas.
Há cerca de uma década, a JANZZ começou a construir a sua ontologia sobre várias taxonomias de ocupação, nomeadamente: CITP-08, ESCO e muitas classificações específicas de países. Ao longo dos anos, a JANZZ incorporou em sua ontologia milhares de novas profissões e funções (por exemplo, pesquisador de mercado, data minerador, especialista em geração milenar, gerente de mídia social, gerente comunitário, etc.) que não existiam anteriormente em nenhuma das taxonomias conhecidas. Além de novos títulos de emprego, a ontologia é constantemente atualizada com a inclusão de novos termos em todos os campos: habilidades, educação, experiência e especializações. O fato de que nossa ontologia é capaz de reconhecer semelhanças e ambiguidades entre empregos e outras áreas relevantes no campo da colocação de trabalho torna-o a ferramenta perfeita para empresas de RH e serviços públicos de emprego. Hoje, a ontologia JANZZ é de longe a maior, mais complexa e completa ontologia de dados de colocação de trabalho do mundo.
Felizmente, alguns governos e empresas escolheram o caminho certo e agora se beneficiam amplamente de nossa tecnologia de última geração. Para mais informação sobre a ontologia da JANZZ, por favor entre em contato conosco: sales@janzz.technology. Agradecemos desde já o seu interesse e teremos todo o gosto em responder a todas as suas perguntas.
[1] Ian Horrocks. 2008. Ontologies and the Semantic Web. URL: http://www.cs.ox.ac.uk/ian.horrocks/Publications/download/2008/Horr08a.pdf [2019.02.01 ]
[2] Larry Lefkowitz. 2018. Semantic Reasoning: The (Almost) Forgotten Half of AI. URL: https://aibusiness.com/semantic-reasoning-ai/ [2019.02.01]
[3] New Idea Engineering. 2018. What’s the difference between Taxonomies and Ontologies? URL: http://www.ideaeng.com/taxonomies-ontologies-0602 [2019.02.01]
[4] Daniel Tunkelang. 2017. Taxonomies and Ontologies. URL: https://queryunderstanding.com/taxonomies-and-ontologies-8e4812a79cb2 [2019.02.01]
[5] Nathan Winant. 2014. What are the advantages of semantic reasoning over machine learning? URL: https://www.quora.com/What-are-the-advantages-of-semantic-reasoning-over-machine-learning [2019.02.01 ]






