Salah satu kata kunci yang paling populer seputar ketenagakerjaan, kemampuan kerja, dan manajemen tenaga kerja adalah keterampilan. Sering kali terdengar banyak kebisingan di sekitar konsep ini dan kata-kata kunci lainnya seperti reskilling, upskilling, pencocokan keterampilan, penyelarasan keterampilan, kesenjangan keterampilan, antisipasi keterampilan, prediksi keterampilan, dan sebagainya. Kita bisa menemukan banyak sekali publikasi dan tulisan yang menjelaskan mengapa keterampilan sangat penting, bagaimana menganalisis penawaran dan permintaan keterampilan, bagaimana mengembangkan kebijakan pasar tenaga kerja yang aktif berdasarkan keterampilan, bagaimana mengelola dan mengembangkan keterampilan karyawan – serta banyak situs yang mencantumkan “keterampilan yang paling banyak dicari” di tahun ini. Kita tentu setuju bahwa keterampilan semakin penting, atau sebagaimana dinyatakan dalam salah satu Gartner Hype Cycles 2020,
Keterampilan adalah […] mata uang baru bagi tenaga kerja. Keterampilan adalah elemen dasar untuk mengelola tenaga kerja dalam industri apa pun. Deteksi dan penilaian keterampilan yang lebih baik dan otomatis memungkinkan ketangkasan organisasi yang jauh lebih besar. Di masa yang penuh ketidakpastian, atau saat terjadi persaingan yang ketat, organisasi dengan data keterampilan yang lebih baik dapat beradaptasi dengan lebih cepat […]. Hal ini meningkatkan produktivitas dan menghemat biaya melalui siklus perencanaan yang lebih baik. [1]
Hal ini tidak hanya berlaku bagi HCM dalam bisnis, tetapi juga bagi manajemen pasar tenaga kerja yang dikelola oleh institusi pemerintah. Mempertimbangkan betapa pentingnya konsep-konsep tersebut secara global, semestinya terdapat pemahaman yang jelas atau setidaknya kesamaan pandangan tentang apa yang dimaksud dengan mata uang yang berharga ini. Namun, dalam banyak konten terkait keterampilan yang diposting secara online, terlihat adanya pola ambiguitas konseptual yang meresap, kurangnya spesifisitas, dan kurangnya peringkasan. Oleh karena itu, dalam tulisan terakhir, di mana telah dibahas beberapa contoh tentang kebisingan seputar pekerjaan dan keterampilan, kami mendorong diskusi yang lebih berbasis fakta. Dalam tulisan ini, kami ingin memaparkan landasan untuk diskusi serupa.
Statitistik 101
Sebagaimana disebutkan dalam tulisan sebelumnya: setiap kali melakukan generalisasi, maka akan berisiko kehilangan relevansi. Terlepas dari berbagai globalisme yang terjadi, dunia terbagi menjadi beberapa kawasan. Dan setiap wilayah memiliki lanskap ekonomi yang berbeda dan kebutuhan keterampilan masing-masing. Beberapa wilayah lebih fokus pada industri tertentu daripada yang lain, dan bahkan ketika membandingkan wilayah dengan industri yang sama, permintaan dan kesenjangan keterampilan bisa sangat bervariasi, seperti yang telah ditunjukkan dalam berbagai penelitian dan laporan (misalnya di sini dan di sini). Jadi, tidak akan pernah ada daftar keterampilan teratas yang signifikan di tingkat global. Keterampilan pemecahan masalah, blockchain, pengembangan aplikasi, dan “keterampilan terbaik” lainnya yang disebarkan di berbagai situs web sama sekali tidak relevan untuk semua aktivitas di seluruh dunia. Selain itu, menghasilkan data yang relevan dan representatif dari profil online dan lowongan pekerjaan tidaklah mudah. Secara umum, data yang dikumpulkan secara online bersifat bias, kelompok tertentu kurang terwakili, sementara kelompok lain terwakili secara berlebihan. Misalnya, terlepas dari semua kegaduhan tentang “keterampilan digital” yang tampaknya sangat penting dan mempercepat, sebagian besar survei yang representatif menyoroti bahwa pasar tenaga kerja Uni Eropa dan Amerika Serikat membutuhkan tingkat keterampilan digital yang umumnya rendah hingga sedang, dengan sekitar 55 hingga 60 persen pekerjaan yang melakukan pemrosesan kata atau entri data sederhana dan mengirim email. Sebanyak 10-15 persen tidak memerlukan keterampilan TIK. Kemudian, hanya sekitar 10-15 persen yang membutuhkan tingkat keterampilan TIK tingkat lanjut. [2] Hal ini menunjukkan bahwa semua publikasi tentang keterampilan terpenting di masa depan dan sebagainya sangat misleading.
Dalam melakukan analisis yang baik dan mengantisipasi keterampilan yang akan dibutuhkan di masa depan, serta memprediksi bagaimana ketentuan-ketentuan ini akan berubah (keterampilan mana yang akan semakin penting dan keterampilan mana yang akan ditinggalkan, atau melakukan pencocokan keterampilan yang berorientasi pada target), pertama-tama kita harus dapat mengenali, memahami, menetapkan, dan mengklasifikasikan keterampilan masa kini dengan benar. Tantangan (dan kelebihan) dari data keterampilan dan pekerjaan akan dibahas secara lebih rinci di artikel berikutnya. Pertama, kita perlu fokus pada aspek yang lebih mendasar, namun sangat krusial yaitu perlu memperjelas apa yang dimaksud dengan keterampilan atau kemampuan dan kompetensi.
Faktanya, ada begitu banyak definisi yang beredar, sehingga cukup sulit untuk mengikutinya, dan inilah salah satu alasan utama mengapa sebagian besar pendekatan dan evaluasi big data gagal total. Oleh karena itu, sangat penting bagi kita untuk menyepakati pemahaman yang sama tentang istilah baru ini.
Apa sebenarnya yang dimaksud dengan keterampilan?
O*NET mendefinisikan keterampilan sebagai kapasitas yang dikembangkan yang memfasilitasi pembelajaran, akuisisi pengetahuan yang lebih cepat atau kinerja kegiatan yang terjadi di seluruh pekerjaan, [3] dan membedakan keterampilan dari kemampuan, pengetahuan, dan keterampilan teknologi dan alat, yang hanya mengacu pada keterampilan dan pengetahuan yang terkait langsung dengan pekerjaan atau yang dapat dialihkan. ESCO, di sisi lain, mendefinisikan keterampilan sebagai kemampuan untuk menerapkan pengetahuan dan menggunakan pengetahuan untuk menyelesaikan tugas dan memecahkan masalah. Selain itu, ESCO hanya mengenal dua kategori utama yaitu keterampilan dan kompetensi, yang – tidak seperti O*NET – juga mencakup sikap dan nilai. Dalam kedua sistem klasifikasi tersebut, terjadi ketumpang tindihan yang signifikan di antara kategori-kategori tersebut. Meskipun demikian, di sisi lain, ESCO hanya merangkum semua konsep ini di bawah istilah keterampilan:
Keterampilan adalah istilah yang mencakup pengetahuan, kompetensi, dan kemampuan untuk melakukan tugas-tugas operasional. Keterampilan dikembangkan melalui pengalaman hidup dan kerja dan juga dapat diperoleh melalui proses pembelajaran. [4]
Tentunya, perbedaan dalam definisi keterampilan ini akan menyebabkan perbedaan dalam pengumpulan dan analisis data, yang pada gilirannya akan mempengaruhi ketahanan ekstrapolasi apa pun berdasarkan data tersebut. Namun, demi kepentingan argumentasi, mari kita asumsikan bahwa terdapat definisi universal tentang keterampilan. Singkatnya, kita akan menganggap keterampilan sebagai suatu kemampuan yang berguna dalam suatu pekerjaan.
Menganalisis keterampilan umum menghasilkan jawaban yang umum pula
Hanya dengan memiliki definisi tertulis tentang suatu keterampilan saja masih jauh dari cukup. Terlepas dari kenyataan bahwa definisi tersebut masih menyisakan banyak ruang untuk penafsiran, terdapat banyak masalah pada tingkat keterampilan individu. Salah satu masalahnya yaitu granularitas, yang sangat berbeda di antara beragam koleksi. Sebagai contoh, taksonomi ESCO saat ini mencakup sekitar 13.500 konsep keterampilan, O*NET di bawah 9.000 (faktanya, hanya 121 di antaranya yang bukan merupakan keterampilan seperti “dapat menggunakan alat/mesin/perangkat lunak/teknologi tertentu”) dan ontologi kami JANZZon! memiliki lebih dari 1.000.000 jenis. Tentu saja, tingkat detail yang diinginkan tergantung pada konteksnya. Namun untuk banyak aplikasi modern dari analisis keterampilan, seperti pencocokan pekerjaan berbasis keterampilan, bimbingan karir, dll, tingkat detail tertentu sangat penting untuk mencapai hasil yang signifikan. Lihatlah daftar “10 keterampilan unggulan tahun 2025” yang diterbitkan oleh World Economic Forum [5]:
- Pemikiran analitis dan inovatif
- Pembelajaran aktif dan strategi pembelajaran
- Pemecahan masalah yang kompleks
- Berpikir kritis dan analisis
- Kreativitas, orisinalitas dan inisiatif
- Leadership dan memiliki pengaruh sosial
- Penggunaan, pemantauan, dan pengendalian teknologi
- Desain teknologi dan pemrograman
- Ketangguhan, toleransi terhadap tekanan, dan fleksibilitas
- Penalaran, pemecahan masalah, dan penciptaan gagasan
Keterampilan ini dipahami secara beragam, tergantung pada konteksnya, misalnya, industri atau aktivitas, sehingga bisa jadi sangat berbeda. Oleh karena itu, keterampilan-keterampilan ini terlalu umum atau kurang spesifik untuk digunakan dalam pencocokan atau untuk statistik yang berguna. Bahkan, untuk sebagian besar pekerjaan, keterampilan ini hampir tidak relevan sama sekali. Atau seberapa sering keterampilan ini muncul dalam lowongan pekerjaan? Keterampilan umum lainnya yang sering dijumpai dalam 10 daftar teratas prediktif dan rekomendasi juga memiliki masalah yang sama, misalnya:
Keterampilan digital: Apa sebenarnya keterampilan ini? Apakah keterampilan ini termasuk mengoperasikan perangkat digital seperti smartphone atau komputer atau berurusan dengan Internet? Apakah kita mengharapkan seseorang dengan keterampilan ini dapat membuat postingan di media sosial, atau benar-benar tahu cara menangani akun media sosial secara profesional? Apakah masuk akal untuk meringkas keterampilan seperti pengetahuan tentang aplikasi pemodelan informasi bangunan yang kompleks dalam perancangan dan perencanaan real estat di bawah keterampilan digital?
Keterampilan project management: Hal ini juga hampir tidak berguna sama sekali jika diambil di luar konteks seperti ini. Sebagian besar karyawan memiliki keterampilan manajemen proyek pada tingkat tertentu, tetapi sangat sulit untuk membandingkan atau mengkategorikan pengetahuan ini di semua peran atau industri. Sebagai contoh, pengetahuan manajemen proyek individu berbeda secara substansial antara seorang pemimpin di lokasi proyek terowongan, manajer proyek untuk aplikasi TI skala kecil, manajer promosi di sektor publik, dan process engineer atau event manager. Jelas, jika industri acara terhenti, seorang manajer proyek tidak bisa begitu saja beralih ke industri konstruksi. Jadi, tidak logis untuk memasukkan semua variasi ini ke dalam satu keterampilan yang “cocok”.
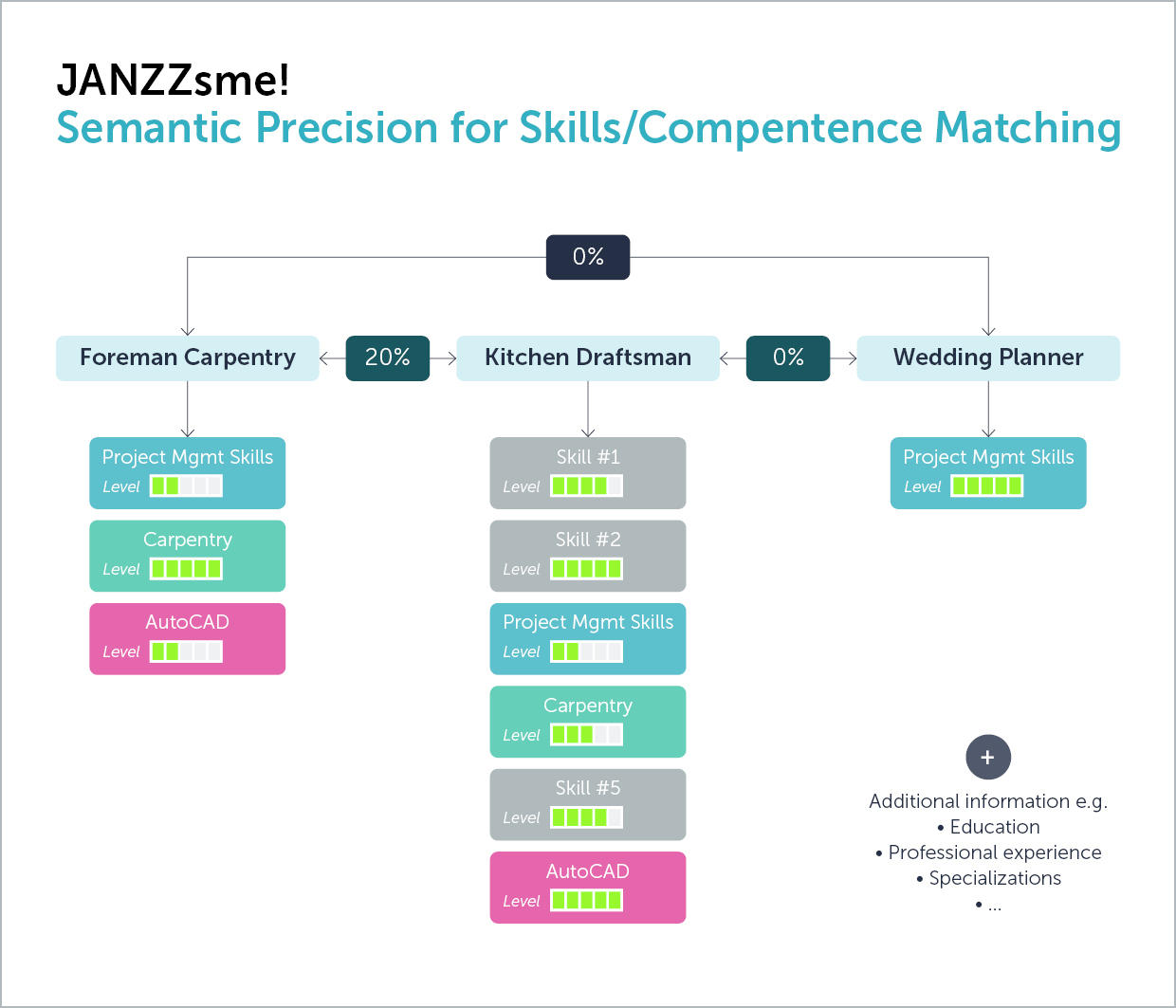
Berpikir multidimensional
Ketepatan dalam hal keterampilan tidak hanya berarti mengidentifikasi keterampilan dan konteksnya dengan jelas, tetapi juga tingkat kemampuannya. Level kemampuan bahasa Inggris yang dibutuhkan oleh seorang pekerja di lokasi konstruksi tentu saja tidak sama dengan tingkat kemampuan seorang penerjemah. Namun, menyusun definisi tingkat yang kuat juga menimbulkan tantangan: Apa yang dimaksud dengan pengetahuan yang “baik” atau “sangat baik”, dan apa yang membedakan seorang “ahli” dalam suatu keterampilan tertentu? Apakah itu pengetahuan yang diperoleh secara teoritis, misalnya, atau pengetahuan yang sudah diterapkan dalam lingkungan profesional yang nyata? Berbeda dengan area big data lainnya, skala dan validasi – jika ada – tidak selalu mengikat. Oleh karena itu, banyak penyedia data jenis ini yang sama sekali mengabaikan level-level tersebut. Dengan demikian, kita kehilangan sejumlah besar informasi yang akan sangat relevan, tidak hanya untuk pencocokan pekerjaan dan bimbingan karier, tetapi juga dalam menganalisis permintaan keterampilan, misalnya, sebagai dasar untuk manajemen tenaga kerja atau pasar tenaga kerja. Apakah kita kekurangan tenaga ahli yang sangat terampil atau karyawan yang memiliki pengetahuan dasar tentang pekerjaan? Tentu saja, tindakan yang tepat akan sangat berbeda tergantung pada jawabannya.
Ungkapkan apa yang Anda maksud
Granularitas dalam hal mengidentifikasi konteks dan tingkat keterampilan tentu saja penting. Namun, masalah utamanya adalah kejelasan. Salah satu dari 10 keterampilan teratas yang dibutuhkan dalam lowongan pekerjaan hampir di seluruh dunia selalu mencantumkan Microsoft Office, yang sekilas terlihat cukup spesifik. Tapi apa maksud sebenarnya dari hal ini? Secara teknis, MS Office adalah sebuah perangkat lunak yang tersedia dalam berbagai paket yang terdiri dari berbagai pilihan aplikasi, yang terus berkembang dari waktu ke waktu. Saat ini, terdiri dari 9 aplikasi: Word, Excel [6], PowerPoint, OneNote, Outlook, Publisher, Access, InfoPath, dan Skype for Business. Jadi, jika seseorang “memiliki keterampilan MS Office”, apakah ini berarti mereka dapat menggunakan semua aplikasi tersebut? Tidak juga. Dan apa artinya bisa menggunakan sebuah aplikasi? Menurut ESCO, seseorang yang dapat “menggunakan Microsoft Office” dapat:
bekerja dengan program standar dalam Microsoft Office pada tingkat mahir. Membuat dokumen dan mengerjakan format dasar, membuat jeda halaman, membuat header atau footer, dan menyisipkan grafik, membuat daftar isi yang dibuat secara otomatis, serta menggabungkan formulir surat dari basis data alamat (biasanya di Excel). Membuat spreadsheet penghitungan otomatis, membuat gambar, dan mengurutkan serta memfilter tabel data. [7]
Banyak orang mungkin berpikir bahwa mereka memiliki keahlian dalam menggunakan MS Office – sampai mereka membaca definisi tersebut. Tampaknya semakin sedikit orang yang tahu tentang potensi penuh sebuah aplikasi, semakin besar kemungkinan orang tersebut diidentifikasi sebagai pengguna yang mahir. Hal ini menjadi semakin jelas ketika kita merujuk pada PowerPoint, yang secara mengejutkan, tidak termasuk dalam keterampilan “menggunakan Microsoft Office” dari ESCO. Sebaliknya, keterampilan ini disebut dengan ‘menggunakan perangkat lunak presentasi’. Ada ribuan aplikasi untuk membuat presentasi, banyak di antaranya yang bekerja dengan cara yang sangat berbeda dengan PowerPoint sehingga membutuhkan pengetahuan atau keterampilan tambahan yang berbeda: Prezi, Perspective, Powtoon, Zoho Show, Apple Keynote, Slidebean, Beautiful.ai, dan masih banyak lagi. Namun, keterampilan “menggunakan perangkat lunak presentasi” hanya secara singkat dijelaskan dalam ESCO sebagai:
“Menggunakan perangkat lunak untuk membuat presentasi digital yang menggabungkan berbagai elemen, seperti grafik, gambar, teks, dan multimedia lainnya.” [8]
Dengan mengesampingkan fakta bahwa terdapat banyak contoh perangkat lunak presentasi, apabila hal tersebut merupakan suatu keterampilan, dalam arti kemampuan yang berguna dalam suatu pekerjaan, maka seharusnya “membuat presentasi” menyiratkan bahwa orang tersebut dapat membuat presentasi yang usable atau bahkan good presentation. Di antara sekian banyak keterampilan, hal ini mencakup kemampuan untuk menyaring informasi menjadi poin-poin penting, serta kemampuan estetika dan storytelling. Namun, dengan kepercayaan diri yang cukup, seseorang yang tidak memiliki keterampilan implisit ini mungkin masih berpikir bahwa mereka mampu membuat presentasi yang luar biasa.
Selain itu, yang diminta oleh pemberi kerja saat mereka meminta keterampilan ini sangat bervariasi. Seseorang yang mencari tenaga kerja di sebuah bisnis mikro mungkin memiliki gambaran yang sangat berbeda tentang keterampilan MS Office dibandingkan perusahaan besar yang mencari spesialis pemasaran. Apabila kita mencoba menafsirkan ungkapan “Microsoft Office” sebagai sebuah keterampilan maka akan menghasilkan begitu banyak penafsiran, sehingga nilai informatif dari “keterampilan Microsoft Office” menjadi sebanding dengan “keterampilan memalu”. Semua orang bisa menggunakan palu, tetapi apakah itu berarti, bahwa setiap orang bisa bekerja dalam profesi apa pun yang berkaitan dengan palu? Tentu saja tidak.

Guru saya sering berkata: Jika yang kamu maksud A, maka katakan A. Cara ini bisa menjadi awal yang baik untuk memulai.
Penilaian (diri sendiri) vs. kenyataan
Seperti yang telah disebutkan di atas, banyak orang yang memiliki gambaran diri yang berbeda dengan kenyataan, sehingga mereka menilai kemampuan mereka secara terlalu rendah atau berlebihan (keahlian memalu, membuat presentasi, atau keahlian lainnya). Selain itu, ada masalah bahwa menyelesaikan kursus atau pendidikan yang semestinya mengajarkan serangkaian keterampilan tidak secara otomatis berarti bahwa kita memiliki keterampilan tersebut, yaitu bahwa kita dapat menerapkannya secara produktif dalam pekerjaan. Selain itu, banyak keterampilan yang tidak terpakai memiliki batas waktu. Namun, setelah terlanjur mencantumkan keahlian tertentu di resume, kita jarang sekali menghapusnya lagi, tak peduli berapa lama kita tidak menggunakannya. Hanya dengan bertanya pada diri sendiri, dapatkah saya menerapkannya secara produktif dalam pekerjaan saya? dapat sangat membantu untuk mendekatkan gambaran yang kita bayangkan dengan kenyataan. Jika memang diinginkan. Seperti halnya menyepakati definisi keterampilan, menstandarkan sebutan dan tingkatan keterampilan atau membuat lebih spesifik dan akurat dapat memberikan kita pemahaman umum yang lebih jelas tentang nilai keterampilan yang berharga ini. Seandainya saja kita mau. Dan kemudian kita dapat beralih ke tantangan dalam menghasilkan data cerdas – yang akan kita telusuri di tulisan berikutnya.
[1] Poitevin, H., “Hype Cycle for Human Capital Management Technology, 2020”, Gartner. 2020.
[2] Thanks to Konstantinos Pouliakas at Cedefop for pointing this out.
[3] https://www.onetcenter.org/content.html
[4] https://www.indeed.com/career-advice/career-development/what-are-skills
[5] http://www3.weforum.org/docs/WEF_Future_of_Jobs_2020.pdf
[6] Read the previous post for our view on Excel.
[7] http://data.europa.eu/esco/skill/f683ae1d-cb7c-4aa1-b9fe-205e1bd23535
[8] http://data.europa.eu/esco/skill/1973c966-f236-40c9-b2d4-5d71a89019be









