Salah satu kata kunci yang paling populer seputar ketenagakerjaan, kemampuan kerja, dan manajemen tenaga kerja adalah keterampilan. Sering kali terdengar banyak kebisingan di sekitar konsep ini dan kata-kata kunci lainnya seperti reskilling, upskilling, pencocokan keterampilan, penyelarasan keterampilan, kesenjangan keterampilan, antisipasi keterampilan, prediksi keterampilan, dan sebagainya. Kita bisa menemukan banyak sekali publikasi dan tulisan yang menjelaskan mengapa keterampilan sangat penting, bagaimana menganalisis penawaran dan permintaan keterampilan, bagaimana mengembangkan kebijakan pasar tenaga kerja yang aktif berdasarkan keterampilan, bagaimana mengelola dan mengembangkan keterampilan karyawan – serta banyak situs yang mencantumkan “keterampilan yang paling banyak dicari” di tahun ini. Kita tentu setuju bahwa keterampilan semakin penting, atau sebagaimana dinyatakan dalam salah satu Gartner Hype Cycles 2020,
Keterampilan adalah […] mata uang baru bagi tenaga kerja. Keterampilan adalah elemen dasar untuk mengelola tenaga kerja dalam industri apa pun. Deteksi dan penilaian keterampilan yang lebih baik dan otomatis memungkinkan ketangkasan organisasi yang jauh lebih besar. Di masa yang penuh ketidakpastian, atau saat terjadi persaingan yang ketat, organisasi dengan data keterampilan yang lebih baik dapat beradaptasi dengan lebih cepat […]. Hal ini meningkatkan produktivitas dan menghemat biaya melalui siklus perencanaan yang lebih baik. [1]
Hal ini tidak hanya berlaku bagi HCM dalam bisnis, tetapi juga bagi manajemen pasar tenaga kerja yang dikelola oleh institusi pemerintah. Mempertimbangkan betapa pentingnya konsep-konsep tersebut secara global, semestinya terdapat pemahaman yang jelas atau setidaknya kesamaan pandangan tentang apa yang dimaksud dengan mata uang yang berharga ini. Namun, dalam banyak konten terkait keterampilan yang diposting secara online, terlihat adanya pola ambiguitas konseptual yang meresap, kurangnya spesifisitas, dan kurangnya peringkasan. Oleh karena itu, dalam tulisan terakhir, di mana telah dibahas beberapa contoh tentang kebisingan seputar pekerjaan dan keterampilan, kami mendorong diskusi yang lebih berbasis fakta. Dalam tulisan ini, kami ingin memaparkan landasan untuk diskusi serupa.
Sebagaimana disebutkan dalam tulisan sebelumnya: setiap kali melakukan generalisasi, maka akan berisiko kehilangan relevansi. Terlepas dari berbagai globalisme yang terjadi, dunia terbagi menjadi beberapa kawasan. Dan setiap wilayah memiliki lanskap ekonomi yang berbeda dan kebutuhan keterampilan masing-masing. Beberapa wilayah lebih fokus pada industri tertentu daripada yang lain, dan bahkan ketika membandingkan wilayah dengan industri yang sama, permintaan dan kesenjangan keterampilan bisa sangat bervariasi, seperti yang telah ditunjukkan dalam berbagai penelitian dan laporan (misalnya di sini dan di sini). Jadi, tidak akan pernah ada daftar keterampilan teratas yang signifikan di tingkat global. Keterampilan pemecahan masalah, blockchain, pengembangan aplikasi, dan “keterampilan terbaik” lainnya yang disebarkan di berbagai situs web sama sekali tidak relevan untuk semua aktivitas di seluruh dunia. Selain itu, menghasilkan data yang relevan dan representatif dari profil online dan lowongan pekerjaan tidaklah mudah. Secara umum, data yang dikumpulkan secara online bersifat bias, kelompok tertentu kurang terwakili, sementara kelompok lain terwakili secara berlebihan. Misalnya, terlepas dari semua kegaduhan tentang “keterampilan digital” yang tampaknya sangat penting dan mempercepat, sebagian besar survei yang representatif menyoroti bahwa pasar tenaga kerja Uni Eropa dan Amerika Serikat membutuhkan tingkat keterampilan digital yang umumnya rendah hingga sedang, dengan sekitar 55 hingga 60 persen pekerjaan yang melakukan pemrosesan kata atau entri data sederhana dan mengirim email. Sebanyak 10-15 persen tidak memerlukan keterampilan TIK. Kemudian, hanya sekitar 10-15 persen yang membutuhkan tingkat keterampilan TIK tingkat lanjut. [2] Hal ini menunjukkan bahwa semua publikasi tentang keterampilan terpenting di masa depan dan sebagainya sangat misleading.
Dalam melakukan analisis yang baik dan mengantisipasi keterampilan yang akan dibutuhkan di masa depan, serta memprediksi bagaimana ketentuan-ketentuan ini akan berubah (keterampilan mana yang akan semakin penting dan keterampilan mana yang akan ditinggalkan, atau melakukan pencocokan keterampilan yang berorientasi pada target), pertama-tama kita harus dapat mengenali, memahami, menetapkan, dan mengklasifikasikan keterampilan masa kini dengan benar. Tantangan (dan kelebihan) dari data keterampilan dan pekerjaan akan dibahas secara lebih rinci di artikel berikutnya. Pertama, kita perlu fokus pada aspek yang lebih mendasar, namun sangat krusial yaitu perlu memperjelas apa yang dimaksud dengan keterampilan atau kemampuan dan kompetensi.
Faktanya, ada begitu banyak definisi yang beredar, sehingga cukup sulit untuk mengikutinya, dan inilah salah satu alasan utama mengapa sebagian besar pendekatan dan evaluasi big data gagal total. Oleh karena itu, sangat penting bagi kita untuk menyepakati pemahaman yang sama tentang istilah baru ini.
O*NET mendefinisikan keterampilan sebagai kapasitas yang dikembangkan yang memfasilitasi pembelajaran, akuisisi pengetahuan yang lebih cepat atau kinerja kegiatan yang terjadi di seluruh pekerjaan, [3] dan membedakan keterampilan dari kemampuan, pengetahuan, dan keterampilan teknologi dan alat, yang hanya mengacu pada keterampilan dan pengetahuan yang terkait langsung dengan pekerjaan atau yang dapat dialihkan. ESCO, di sisi lain, mendefinisikan keterampilan sebagai kemampuan untuk menerapkan pengetahuan dan menggunakan pengetahuan untuk menyelesaikan tugas dan memecahkan masalah. Selain itu, ESCO hanya mengenal dua kategori utama yaitu keterampilan dan kompetensi, yang – tidak seperti O*NET – juga mencakup sikap dan nilai. Dalam kedua sistem klasifikasi tersebut, terjadi ketumpang tindihan yang signifikan di antara kategori-kategori tersebut. Meskipun demikian, di sisi lain, ESCO hanya merangkum semua konsep ini di bawah istilah keterampilan:
Keterampilan adalah istilah yang mencakup pengetahuan, kompetensi, dan kemampuan untuk melakukan tugas-tugas operasional. Keterampilan dikembangkan melalui pengalaman hidup dan kerja dan juga dapat diperoleh melalui proses pembelajaran. [4]
Tentunya, perbedaan dalam definisi keterampilan ini akan menyebabkan perbedaan dalam pengumpulan dan analisis data, yang pada gilirannya akan mempengaruhi ketahanan ekstrapolasi apa pun berdasarkan data tersebut. Namun, demi kepentingan argumentasi, mari kita asumsikan bahwa terdapat definisi universal tentang keterampilan. Singkatnya, kita akan menganggap keterampilan sebagai suatu kemampuan yang berguna dalam suatu pekerjaan.
Hanya dengan memiliki definisi tertulis tentang suatu keterampilan saja masih jauh dari cukup. Terlepas dari kenyataan bahwa definisi tersebut masih menyisakan banyak ruang untuk penafsiran, terdapat banyak masalah pada tingkat keterampilan individu. Salah satu masalahnya yaitu granularitas, yang sangat berbeda di antara beragam koleksi. Sebagai contoh, taksonomi ESCO saat ini mencakup sekitar 13.500 konsep keterampilan, O*NET di bawah 9.000 (faktanya, hanya 121 di antaranya yang bukan merupakan keterampilan seperti “dapat menggunakan alat/mesin/perangkat lunak/teknologi tertentu”) dan ontologi kami JANZZon! memiliki lebih dari 1.000.000 jenis. Tentu saja, tingkat detail yang diinginkan tergantung pada konteksnya. Namun untuk banyak aplikasi modern dari analisis keterampilan, seperti pencocokan pekerjaan berbasis keterampilan, bimbingan karir, dll, tingkat detail tertentu sangat penting untuk mencapai hasil yang signifikan. Lihatlah daftar “10 keterampilan unggulan tahun 2025” yang diterbitkan oleh World Economic Forum [5]:
Keterampilan ini dipahami secara beragam, tergantung pada konteksnya, misalnya, industri atau aktivitas, sehingga bisa jadi sangat berbeda. Oleh karena itu, keterampilan-keterampilan ini terlalu umum atau kurang spesifik untuk digunakan dalam pencocokan atau untuk statistik yang berguna. Bahkan, untuk sebagian besar pekerjaan, keterampilan ini hampir tidak relevan sama sekali. Atau seberapa sering keterampilan ini muncul dalam lowongan pekerjaan? Keterampilan umum lainnya yang sering dijumpai dalam 10 daftar teratas prediktif dan rekomendasi juga memiliki masalah yang sama, misalnya:
Keterampilan digital: Apa sebenarnya keterampilan ini? Apakah keterampilan ini termasuk mengoperasikan perangkat digital seperti smartphone atau komputer atau berurusan dengan Internet? Apakah kita mengharapkan seseorang dengan keterampilan ini dapat membuat postingan di media sosial, atau benar-benar tahu cara menangani akun media sosial secara profesional? Apakah masuk akal untuk meringkas keterampilan seperti pengetahuan tentang aplikasi pemodelan informasi bangunan yang kompleks dalam perancangan dan perencanaan real estat di bawah keterampilan digital?
Keterampilan project management: Hal ini juga hampir tidak berguna sama sekali jika diambil di luar konteks seperti ini. Sebagian besar karyawan memiliki keterampilan manajemen proyek pada tingkat tertentu, tetapi sangat sulit untuk membandingkan atau mengkategorikan pengetahuan ini di semua peran atau industri. Sebagai contoh, pengetahuan manajemen proyek individu berbeda secara substansial antara seorang pemimpin di lokasi proyek terowongan, manajer proyek untuk aplikasi TI skala kecil, manajer promosi di sektor publik, dan process engineer atau event manager. Jelas, jika industri acara terhenti, seorang manajer proyek tidak bisa begitu saja beralih ke industri konstruksi. Jadi, tidak logis untuk memasukkan semua variasi ini ke dalam satu keterampilan yang “cocok”.
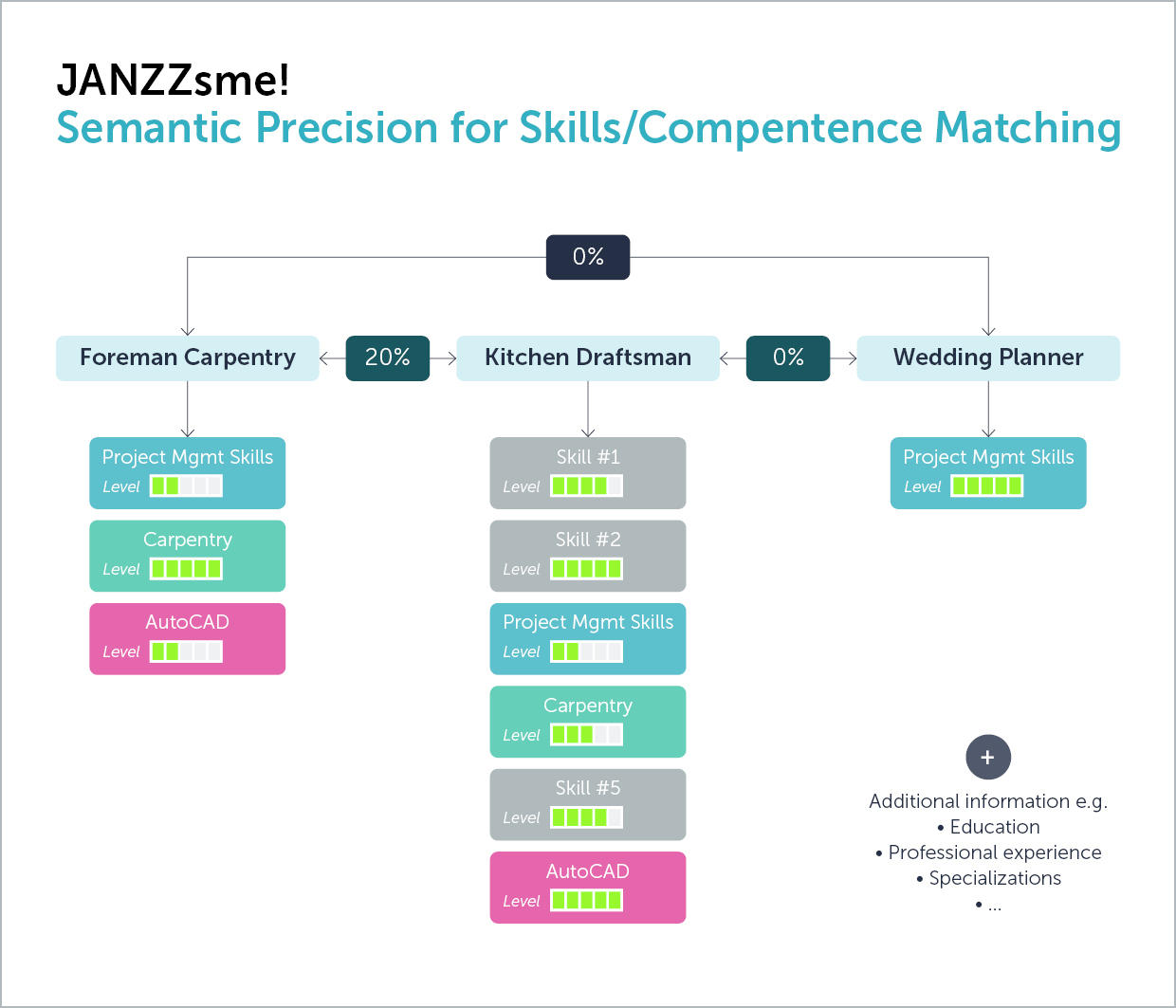
Ketepatan dalam hal keterampilan tidak hanya berarti mengidentifikasi keterampilan dan konteksnya dengan jelas, tetapi juga tingkat kemampuannya. Level kemampuan bahasa Inggris yang dibutuhkan oleh seorang pekerja di lokasi konstruksi tentu saja tidak sama dengan tingkat kemampuan seorang penerjemah. Namun, menyusun definisi tingkat yang kuat juga menimbulkan tantangan: Apa yang dimaksud dengan pengetahuan yang “baik” atau “sangat baik”, dan apa yang membedakan seorang “ahli” dalam suatu keterampilan tertentu? Apakah itu pengetahuan yang diperoleh secara teoritis, misalnya, atau pengetahuan yang sudah diterapkan dalam lingkungan profesional yang nyata? Berbeda dengan area big data lainnya, skala dan validasi – jika ada – tidak selalu mengikat. Oleh karena itu, banyak penyedia data jenis ini yang sama sekali mengabaikan level-level tersebut. Dengan demikian, kita kehilangan sejumlah besar informasi yang akan sangat relevan, tidak hanya untuk pencocokan pekerjaan dan bimbingan karier, tetapi juga dalam menganalisis permintaan keterampilan, misalnya, sebagai dasar untuk manajemen tenaga kerja atau pasar tenaga kerja. Apakah kita kekurangan tenaga ahli yang sangat terampil atau karyawan yang memiliki pengetahuan dasar tentang pekerjaan? Tentu saja, tindakan yang tepat akan sangat berbeda tergantung pada jawabannya.
Granularitas dalam hal mengidentifikasi konteks dan tingkat keterampilan tentu saja penting. Namun, masalah utamanya adalah kejelasan. Salah satu dari 10 keterampilan teratas yang dibutuhkan dalam lowongan pekerjaan hampir di seluruh dunia selalu mencantumkan Microsoft Office, yang sekilas terlihat cukup spesifik. Tapi apa maksud sebenarnya dari hal ini? Secara teknis, MS Office adalah sebuah perangkat lunak yang tersedia dalam berbagai paket yang terdiri dari berbagai pilihan aplikasi, yang terus berkembang dari waktu ke waktu. Saat ini, terdiri dari 9 aplikasi: Word, Excel [6], PowerPoint, OneNote, Outlook, Publisher, Access, InfoPath, dan Skype for Business. Jadi, jika seseorang “memiliki keterampilan MS Office”, apakah ini berarti mereka dapat menggunakan semua aplikasi tersebut? Tidak juga. Dan apa artinya bisa menggunakan sebuah aplikasi? Menurut ESCO, seseorang yang dapat “menggunakan Microsoft Office” dapat:
bekerja dengan program standar dalam Microsoft Office pada tingkat mahir. Membuat dokumen dan mengerjakan format dasar, membuat jeda halaman, membuat header atau footer, dan menyisipkan grafik, membuat daftar isi yang dibuat secara otomatis, serta menggabungkan formulir surat dari basis data alamat (biasanya di Excel). Membuat spreadsheet penghitungan otomatis, membuat gambar, dan mengurutkan serta memfilter tabel data. [7]
Banyak orang mungkin berpikir bahwa mereka memiliki keahlian dalam menggunakan MS Office – sampai mereka membaca definisi tersebut. Tampaknya semakin sedikit orang yang tahu tentang potensi penuh sebuah aplikasi, semakin besar kemungkinan orang tersebut diidentifikasi sebagai pengguna yang mahir. Hal ini menjadi semakin jelas ketika kita merujuk pada PowerPoint, yang secara mengejutkan, tidak termasuk dalam keterampilan “menggunakan Microsoft Office” dari ESCO. Sebaliknya, keterampilan ini disebut dengan ‘menggunakan perangkat lunak presentasi’. Ada ribuan aplikasi untuk membuat presentasi, banyak di antaranya yang bekerja dengan cara yang sangat berbeda dengan PowerPoint sehingga membutuhkan pengetahuan atau keterampilan tambahan yang berbeda: Prezi, Perspective, Powtoon, Zoho Show, Apple Keynote, Slidebean, Beautiful.ai, dan masih banyak lagi. Namun, keterampilan “menggunakan perangkat lunak presentasi” hanya secara singkat dijelaskan dalam ESCO sebagai:
“Menggunakan perangkat lunak untuk membuat presentasi digital yang menggabungkan berbagai elemen, seperti grafik, gambar, teks, dan multimedia lainnya.” [8]
Dengan mengesampingkan fakta bahwa terdapat banyak contoh perangkat lunak presentasi, apabila hal tersebut merupakan suatu keterampilan, dalam arti kemampuan yang berguna dalam suatu pekerjaan, maka seharusnya “membuat presentasi” menyiratkan bahwa orang tersebut dapat membuat presentasi yang usable atau bahkan good presentation. Di antara sekian banyak keterampilan, hal ini mencakup kemampuan untuk menyaring informasi menjadi poin-poin penting, serta kemampuan estetika dan storytelling. Namun, dengan kepercayaan diri yang cukup, seseorang yang tidak memiliki keterampilan implisit ini mungkin masih berpikir bahwa mereka mampu membuat presentasi yang luar biasa.
Selain itu, yang diminta oleh pemberi kerja saat mereka meminta keterampilan ini sangat bervariasi. Seseorang yang mencari tenaga kerja di sebuah bisnis mikro mungkin memiliki gambaran yang sangat berbeda tentang keterampilan MS Office dibandingkan perusahaan besar yang mencari spesialis pemasaran. Apabila kita mencoba menafsirkan ungkapan “Microsoft Office” sebagai sebuah keterampilan maka akan menghasilkan begitu banyak penafsiran, sehingga nilai informatif dari “keterampilan Microsoft Office” menjadi sebanding dengan “keterampilan memalu”. Semua orang bisa menggunakan palu, tetapi apakah itu berarti, bahwa setiap orang bisa bekerja dalam profesi apa pun yang berkaitan dengan palu? Tentu saja tidak.

Guru saya sering berkata: Jika yang kamu maksud A, maka katakan A. Cara ini bisa menjadi awal yang baik untuk memulai.
Seperti yang telah disebutkan di atas, banyak orang yang memiliki gambaran diri yang berbeda dengan kenyataan, sehingga mereka menilai kemampuan mereka secara terlalu rendah atau berlebihan (keahlian memalu, membuat presentasi, atau keahlian lainnya). Selain itu, ada masalah bahwa menyelesaikan kursus atau pendidikan yang semestinya mengajarkan serangkaian keterampilan tidak secara otomatis berarti bahwa kita memiliki keterampilan tersebut, yaitu bahwa kita dapat menerapkannya secara produktif dalam pekerjaan. Selain itu, banyak keterampilan yang tidak terpakai memiliki batas waktu. Namun, setelah terlanjur mencantumkan keahlian tertentu di resume, kita jarang sekali menghapusnya lagi, tak peduli berapa lama kita tidak menggunakannya. Hanya dengan bertanya pada diri sendiri, dapatkah saya menerapkannya secara produktif dalam pekerjaan saya? dapat sangat membantu untuk mendekatkan gambaran yang kita bayangkan dengan kenyataan. Jika memang diinginkan. Seperti halnya menyepakati definisi keterampilan, menstandarkan sebutan dan tingkatan keterampilan atau membuat lebih spesifik dan akurat dapat memberikan kita pemahaman umum yang lebih jelas tentang nilai keterampilan yang berharga ini. Seandainya saja kita mau. Dan kemudian kita dapat beralih ke tantangan dalam menghasilkan data cerdas – yang akan kita telusuri di tulisan berikutnya.
[1] Poitevin, H., “Hype Cycle for Human Capital Management Technology, 2020”, Gartner. 2020.
[2] Thanks to Konstantinos Pouliakas at Cedefop for pointing this out.
[3] https://www.onetcenter.org/content.html
[4] https://www.indeed.com/career-advice/career-development/what-are-skills
[5] http://www3.weforum.org/docs/WEF_Future_of_Jobs_2020.pdf
[6] Read the previous post for our view on Excel.
[7] http://data.europa.eu/esco/skill/f683ae1d-cb7c-4aa1-b9fe-205e1bd23535
[8] http://data.europa.eu/esco/skill/1973c966-f236-40c9-b2d4-5d71a89019be

Setelah membahas topik keterampilan beberapa hari yang lalu melalui artikel Pengetahuan ≠ Keterampilan ≠ Pengalaman – atau alasan adanya perbedaan konsisten antara istilah-istilah demikian menjadi semakin penting, kali ini kita akan membahas topik ini secara lebih mendalam.
Pencocokan pekerjaan merupakan sebuah proses yang cukup populer dalam beberapa tahun terakhir sebagai suatu alat yang digunakan untuk mencocokkan individu dengan lowongan pekerjaan berdasarkan keterampilan mereka. Meskipun konsep pencocokan keterampilan terlihat masuk akal, namun sebenarnya hal ini kurang sesuai jika mencocokkan keterampilan tanpa mengetahui level yang tepat dari setiap jenis keterampilan yang eksplisit maupun implisit, » Selengkapnya: A rose ≠ is a rose ≠ is a rose – mengapa mencocokkan keterampilan tanpa level yang tepat sama saja sia-sia. »

Pengetahuan, keterampilan, dan pengalaman adalah tiga komponen penting yang membentuk kompetensi seseorang dalam bidang apa pun. Sayangnya, saat ini istilah-istilah tersebut digunakan secara bergatian atau interchangeably, namun memiliki arti yang sangat berbeda.
Pengetahuan mengacu pada pemahaman intelektual tentang fakta, konsep, dan teori yang terkait dengan bidang tertentu, yang diperoleh melalui pendidikan, seperti dengan membaca buku, menghadiri kuliah, dan berpartisipasi dalam program pelatihan. Pengetahuan sangat penting karena memberikan dasar serta pondasi untuk mengembangkan keterampilan yang memungkinkan individu untuk memahami sebuah alasan di balik praktik atau prosedur tertentu. Keterampilan, di sisi lain, mengacu pada kemampuan untuk melakukan tugas dengan akurasi dan kualitas yang konsisten. Hal ini merupakan penerapan pengetahuan dalam pengaturan praktis. Keterampilan dikembangkan melalui latihan, pengulangan, dan umpan balik dari mentor atau supervisor yang berpengalaman. Semakin sering seseorang mempraktikkan suatu keterampilan, biasanya mereka akan mengalami peningkatan penguasaan keterampilan tersebut. Pengalaman mengacu pada paparan seseorang terhadap bidang atau area pekerjaan tertentu yang berasal dari pengalaman kerja, program magang, menjadi sukarelawan, dan aplikasi praktis lainnya dari pengetahuan dan keterampilan. Pengalaman merupakan sesuatu yang sangat berharga karena memberikan seorang individu pemahaman dunia nyata tentang tantangan yang mungkin mereka hadapi. Hal ini membantu mereka mengidentifikasi solusi terhadap suatu potensi masalah dan memberikan peluang untuk pertumbuhan dan perkembangan pribadi.
Di sisi lain, keterampilan terapan mengacu pada penggunaan praktis suatu keterampilan dalam pekerjaan atau bidang tertentu. Keterampilan terapan adalah kemampuan yang telah dikembangkan oleh seseorang melalui latihan dan pengalaman dan dapat langsung diterapkan dalam situasi kehidupan nyata. Keterampilan terapan sangat penting karena merupakan satu-satunya yang memungkinkan seseorang untuk melakukan pekerjaan mereka secara efisien dan efektif. Meskipun keterampilan dan pengalaman sama-sama penting, namun pengalaman selalu lebih baik daripada sekadar keterampilan saja. Hal ini disebabkan karena hanya pengalaman yang memungkinkan individu untuk menerapkan pengetahuan dan keterampilan mereka dalam situasi praktis. Pengalaman juga memungkinkan seseorang untuk mengembangkan kemampuan pemecahan masalah, komunikasi, dan keterampilan penting lainnya yang sulit dipelajari hanya dengan membaca atau mengikuti pelatihan. Pengalaman juga memberikan pemahaman yang lebih mendalam tentang kompleksitas bidang tertentu. Hal ini membuat mereka lebih mudah beradaptasi dengan perubahan dan cenderung berhasil dalam situasi yang menantang. Selain itu, pengalaman memberikan kesempatan kepada individu untuk belajar dari kesalahan dan mengembangkan sikap pantang menyerah.
Sederhananya, pengetahuan, keterampilan, dan pengalaman adalah komponen penting yang membentuk kompetensi seseorang dalam bidang apa pun. Sekali lagi, meski keterampilan dan pengetahuan sama berharganya, pengalaman selalu lebih baik daripada keterampilan saja. Penerapan praktis dari keterampilan dan pengetahuan yang diperoleh melalui pengalaman akan memberikan pemahaman yang lebih dalam akan bidang mereka, keterampilan dalam pemecahan masalah, dan kemampuan untuk beradaptasi dengan tantangan baru.
Inilah mengapa pentingnya membedakan antara pengetahuan, keterampilan, dan pengalaman dalam hal pencocokan, perekrutan, dan penerimaan karyawan, karena setiap dimensi membawa nilai uniknya masing-masing dalam proses tersebut. Ketika merekrut seorang kandidat, organisasi harus mempertimbangkan persyaratan spesifik dari pekerjaan atau posisi yang akan diisi. Misalnya, jika sebuah organisasi melakukan perekrutan untuk posisi teknis, pengetahuan yang telah terbukti/keterampilan terapan dalam bahasa pengkodean dan pemrograman tertentu mungkin lebih penting daripada pengetahuan tentang konsep teoretis yang terkait dengan bidang tersebut.
Sementara itu, meskipun pengetahuan dan keterampilan sangat penting, pengalaman memberikan wawasan yang paling berharga dan relevan terhadap pekerjaan dan bidangnya. Sebagai contoh, kandidat dengan keterampilan pemrograman yang luar biasa namun lebih bersifat teoretis mungkin bukan pilihan yang paling tepat untuk suatu posisi jika mereka tidak memiliki pengalaman kerja yang relevan. Penting juga untuk menyeimbangkan dimensi yang berbeda dalam proses pencocokan dan perekrutan berbasis bukti. Beberapa organisasi mungkin lebih menekankan pada keterampilan teknis, sementara yang lain mungkin fokus pada keterampilan lunak seperti komunikasi dan kerja sama tim. Oleh karena itu, organisasi perlu memiliki pemahaman yang jelas tentang persyaratan spesifik dari peran serta kualifikasi yang diinginkan dan menentukan bobot pengetahuan, keterampilan, dan pengalaman yang sesuai. Pada saat yang sama, terutama lembaga atau perusahaan dengan fokus yang kuat hanya pada keterampilan yang berhubungan dengan pekerjaan, tidak boleh mengabaikan faktor-faktor lain seperti sikap, kecocokan budaya, dan potensi untuk berkembang. Faktor-faktor ini dapat berperan penting dalam memprediksi kesuksesan dan retensi jangka panjang.
Oleh karena itu, proses pencocokan dan perekrutan yang seimbang yang mempertimbangkan seluruh dimensi ini secara holistik dapat membantu berbagai lembaga maupun perusahaan untuk mengidentifikasi kandidat terbaik bagi lowongan yang mereka buka. Dengan berfokus secara eksklusif pada latar belakang, pendidikan dan pengetahuan, maupun pada keterampilan atau soft skill yang begitu tersebar luas saat ini, tidak akan mampu memberikan hasil pencocokan berbasis kecerdasan buatan atau kecerdasan manusia yang akurat dan berkesinambungan, serta tidak juga menghasilkan suatu keberhasilan dalam perekrutan. Maka, mari kita mulai atasi persoalan istilah dan dimensi ini dengan cara yang berbeda, yang akan memberikan lebih banyak lagi manfaat bagi kita semua.

Berbagai negara di seluruh dunia, khususnya negara-negara berkembang di Asia Tenggara, Afrika, dan Amerika Latin, menghadapi tantangan pasar tenaga kerja yang kian besar. Semakin banyak angkatan kerja dengan latar belakang akademis yang terlampau tinggi kesulitan mendapatkan pekerjaan sesuai dengan bidang dan kualifikasi mereka. Di sisi lain, terdapat keterbatasan tenaga kerja terampil dengan latar belakang teknis atau kejuruan, sehingga banyak pekerjaan yang tidak dapat terpenuhi. Keduanya merupakan fenomena yang tentunya merugikan ekosistem pasar kerja akibat ketidaksesuaian keterampilan yang terus meningkat di seluruh dunia.
Fenomena ini disebabkan oleh beberapa faktor. Salah satu pendorong utamanya yaitu penekanan budaya yang terjadi di tengah masyarakat akan pentingnya sebuah pendidikan tinggi. Selama bertahun-tahun, terdapat kepercayaan yang meluas bahwa gelar sarjana merupakan kunci kesuksesan dan stabilitas finansial. Akibatnya, banyak orang menempuh pendidikan tinggi yang seringkali menghabiskan biaya yang besar, dengan harapan dapat meningkatkan kemampuan kerja dan prospek pekerjaan di masa depan. Namun, pasar tenaga kerja senantiasa berkembang seiring dengan berjalannya waktu. Banyak perusahaan kini mengisi lowongan pekerjaan yang sebelumnya mewajibkan gelar sarjana sebagai syarat utama, menjadi lowongan yang cukup diisi dengan pekerja berlatar belakang pendidikan teknis atau kejuruan. Kemajuan teknologi dan otomatisasi semakin mendorong pergeseran ini melalui pendefinisian ulang berbagai pekerjaan tradisional dan menciptakan posisi baru yang membutuhkan keahlian secara lebih spesifik. Kekurangan pekerja berlatar belakang teknis atau kejuruan maupun lulusan vokasi merupakan masalah serius bagi banyak industri, terutama di bidang konstruksi, perdagangan kerajinan tangan, manufaktur, transportasi, dan sektor kesehatan dan perawatan. Industri-industri tersebut membutuhkan lebih banyak lagi pekerja dengan keahlian khusus yang seringkali hanya dapat diperoleh melalui pengalaman atau pelatihan, tidak terbatas pada pendidikan tinggi saja.
Sejumlah negara telah mengambil langkah untuk berinvestasi dalam pendidikan dan pelatihan teknis maupun kejuruan sebagai upaya mengatasi tantangan ini. Investasi tersebut mencakup program pendanaan untuk melatih siswa dalam keterampilan teknis, mulai dari pertukangan dan pemasangan pipa hingga pemrograman komputer dan robotika. Namun, dalam banyak kasus, pemerintah, pemangku kepentingan, pembuat kebijakan, dan industri masih cenderung ragu-ragu dalam menentukan Langkah ini, menyusun program yang masih cenderung bersifat parsial, sementara pendanaan tergolong minim. Hal ini harus segera diubah apabila kita ingin mengurai dan mengatasi masalah kelangkaan tenaga ahli di bidang ini sebelum terlambat.
Secara keseluruhan, tantangan dari pekerja dengan overkualifikasi dan kekurangan pekerja dengan latar belakang teknis atau kejuruan merupakan suatu masalah kompleks yang membutuhkan solusi dari berbagai pihak. Dengan berinvestasi pada pendidikan dan pelatihan berkualitas tinggi yang berorientasi pada masa depan dan melakukan evaluasi diri akan pentingnya penekanan budaya yang dititikberatkan pada sebuah status pendidikan tinggi, kita semua dapat turut memastikan bahwa para pekerja dapat meningkatkan kelayakan kerja mereka, sehingga mendapatkan akses meraih karier yang menjanjikan serta berkontribusi pada pertumbuhan dan kesuksesan ekonomi yang berkelanjutan.
JANZZilms!, sistem manajemen pasar tenaga kerja real-time terintegrasi yang inteligen, menunjukkan dengan tepat dan mengkuantifikasi jenis-jenis fakta ini pada setiap tingkat perincian yang memungkinkan. Kami menyediakan wawasan dan dasar faktual yang diperlukan untuk menginisiasi, memantau, dan terus menerus mengembangkan solusi secara tepat dan akurat bagi manajemen pasar tenaga kerja.
JANZZilms! – from guessing to knowing.

Dalam beberapa tahun terakhir, terdapat sejumlah banyak tulisan, artikel, dan laporan tentang bagaimana AI dan otomasi akan membentuk masa depan pekerjaan. Tergantung dengan perspektif atau agenda para penulisnya, tulisan-tulisan tersebut biasanya mengarah pada salah satu dari dua cara berikut ini: apakah teknologi baru akan mengancam pekerjaan dan memiliki dampak buruk terhadap pasar tenaga kerja, atau justru akan menciptakan masa depan yang lebih baik dan lebih cerah bagi semua orang dengan mengeliminasi pekerjaan-pekerjaan yang monoton dan menghasilkan ragam pekerjaan yang lebih baik dan lebih menarik? ChatGPT, sebagai contohnya, telah memicu antusiasme yang cukup menghebohkan dunia maya, berayun layaknya pendulum di antara dua pendapat yang sangat berbeda. Di satu sisi, ada banyak sekali tanggapan euforia, dengan banyaknya orang yang berandai-andai tentang bagaimana teknologi yang konon sangat cerdas ini dapat dimanfaatkan untuk meningkatkan kinerja kita – mulai dari jurnalisme, pengodean, analisis data, hingga manajemen proyek dan mengerjakan tugas-tugas sekolah. Di sisi lain, banyak yang menyuarakan kekhawatiran tentang potensi tindak penyalahgunaan, termasuk kemampuan ChatGPT menulis kode malware dan e-mail phishing, menyebarkan informasi yang salah, mengungkapkan informasi pribadi, dan menggantikan peran manusia di tempat kerja. Dalam artikel ini, kami ingin mencoba mengambil pandangan yang lebih bernuansa dengan membahas argumen dan klaim yang paling umum dan membandingkannya dengan fakta yang ada. Namun sebelum kita mulai membahas hal ini, mari kita jelaskan terlebih dahulu apa itu transformasi digital yang digerakkan oleh AI. Singkatnya, transformasi digital berbasis AI mencakup otomatisasi, penggunaan teknologi AI untuk menyelesaikan tugas-tugas yang tidak ingin dilakukan oleh manusia atau yang tidak dapat dilakukan oleh manusia – seperti yang kita lakukan di masa lalu, pada revolusi industri pertama, kedua, dan ketiga.
Setiap terjadi suatu revolusi, muncul ketakutan bahwa pekerja manusia akan menjadi usang dan tersingkirkan. Sehingga sebetulnya mengapa ada keinginan dari diri manusia untuk mengotomatisasi suatu pekerjaan? Meskipun dalam beberapa kasus, para penemu teknologi hanya tertarik pada prestasi penemuan itu sendiri, namun lebih seringnya, sebuah penemuan atau pengembangan didorong oleh kepentingan bisnis. Seperti halnya adopsi yang meluas. Dan di era apa pun, jarang ditemukan bisnis yang memiliki tujuan lain selain tetap kompetitif dan meningkatkan keuntungan. Alat tenun stoking atau stocking looms ditemukan pada abad ke-16 untuk meningkatkan produktivitas dan menurunkan biaya operasional dengan menggantikan tenaga kerja manusia. Mesin tenaga uap pada abad ke-19 di industri dan pabrik-pabrik serta mesin pertanian juga digunakan untuk alasan serupa. Robot pembuat kendaraan di pertengahan kedua abad ke-20 juga demikian. Baik teknologi traktor, jalur perakitan, atau spreadsheet, memiliki tujuan utama serupa yaitu untuk menggantikan otot manusia dengan tenaga mekanis, menggantikan pekerjaan tangan manusia dengan konsistensi mesin, dan mengatasi persoalan “humanware” yang lambat dan rentan kesalahan dengan perhitungan digital. Namun sejauh ini, meskipun banyak pekerjaan yang hilang karena otomatisasi, pekerjaan baru lainnya juga bermunculan. Produksi yang meningkat secara besar-besaran membutuhkan pekerjaan yang berkaitan dengan peningkatan distribusi. Pergeseran juga terjadi pada kendaraan seperti mobil penumpang yang telah menggantikan tenaga kuda dan pekerjaan terkait berkuda, serta meningkatkan mobilitas pribadi, pekerjaan justru muncul dari industri kuliner dan akomodasi yang berkembang. Meningkatnya daya komputasi yang digunakan untuk menggantikan tugas-tugas manusia di kantor juga memunculkan produk dan industri gim yang sepenuhnya baru. Selain itu, seiring dengan meningkatnya kekayaan dan pertumbuhan populasi yang menyertai perkembangan tersebut, permintaan akan rekreasi dan konsumsi juga meningkat, sehingga mendorong sektor-sektor ini dan menciptakan lapangan kerja – meskipun tidak sebanyak yang dibayangkan, seperti yang akan kita lihat di bawah ini. Namun, kita tidak bisa berasumsi bahwa revolusi saat ini akan mengikuti pola yang sama dan menciptakan lebih banyak lapangan kerja dan kekayaan daripada yang akan tersingkirkan hanya karena hal ini terjadi di masa lampau. Tidak seperti teknologi mekanik dan komputasi dasar, teknologi AI tidak hanya memiliki potensi untuk menggantikan pekerja berupah rendah saja, misalnya, dengan robot pembersih atau robot pertanian. Akan tetapi, mereka juga mulai mengungguli keahlian para pekerja profesional seperti ahli patologi dalam mendiagnosis kanker dan profesional medis lainnya dalam mendiagnosis dan merawat pasien. Kini, teknologi tersebut juga mengambil alih tugas-tugas kreatif seperti menulis kreatif, memilih adegan untuk trailer film, atau memproduksi seni digital. Kita tidak perlu berasumsi akan masa depan yang suram dengan berkurangnya pekerjaan dan menurunnya angka kekayaan. Namun kita harus ingat bahwa, dalam berbagai kasus, mengganti pekerja berupah tinggi dengan solusi AI saat ini lebih hemat biaya dibandingkan dengan tenaga kerja berupah rendah seperti para pekerja tekstil di Bangladesh.
Oleh karena itu, untuk memperoleh perspektif lain yang sedikit berbeda, mari kita simak klaim-klaim yang paling sering dikemukakan dalam beberapa waktu belakangan ini dan bagaimana klaim-klaim tersebut dapat dipertanggungjawabkan.
Pernyataan ini merupakan argumen utama yang dikemukakan dalam skenario utopis/distopis, termasuk berdasarkan laporan dari WEF (97 juta pekerjaan baru melawan 85 juta pekerjaan yang hilang di 26 negara pada tahun 2025), PwC (“kehilangan pekerjaan akibat otomasi kemungkinan besar akan diimbangi secara luas untuk jangka panjang oleh pekerjaan baru yang diciptakan”), Forrester (kehilangan pekerjaan sebesar 29% pada tahun 2030 dengan hanya 13% pekerjaan yang dapat dikompensasikan), dan masih banyak lagi. Bagaimanapun juga, setiap perubahan yang terjadi dapat menimbulkan tantangan yang signifikan. Seperti pernyataan BCG dalam laporan terbaru tentang topik ini, “total pekerjaan yang hilang atau bertambah adalah indikator yang sangat sederhana” untuk memperkirakan dampak digitalisasi. Perubahan bersih nol atau bahkan peningkatan jumlah pekerjaan dapat menyebabkan asimetri besar di pasar tenaga kerja dengan kekurangan talenta yang dramatis di beberapa industri atau pekerjaan dan surplus pekerja yang sangat besar serta pengangguran di industri lain. Di sisi lain, alih-alih menyebabkan pengangguran – atau setidaknya underemployment, berkurangnya lapangan pekerjaan juga dapat menyebabkan lebih banyak pembagian pekerjaan dan jumlah jam kerja yang lebih pendek. Sekali lagi, meskipun hal ini mungkin terdengar menarik secara teori, hal ini menimbulkan pertanyaan tambahan: Bagaimana gaji dan tunjangan akan terdampak? Dan siapa yang akan mendapatkan keuntungan moneter terbesar? Apakah perusahaan? Pekerja? Pemerintah? Memang masih terlalu dini untuk melihat dampak adopsi AI yang meluas terhadap pekerjaan atau upah secara keseluruhan. Namun, apa yang dihasilkan di masa lampau yaitu revolusi industri tidak menjamin hasil yang sama di masa mendatang. Bahkan sejarah pun mencatat bahwa pertumbuhan lapangan kerja dan kekayaan tidak semulus yang sering digambarkan. Rasio lapangan kerja terhadap populasi usia kerja telah meningkat di negara-negara OECD sejak tahun 1970, dari 64% menjadi 69% pada tahun 2022. [1] Namun, sebagian besar dari peningkatan ini dapat dikaitkan dengan tingkat partisipasi tenaga kerja yang lebih tinggi, terutama di kalangan perempuan. Dan peningkatan kekayaan ini tentu saja tidak terdistribusi secara merata, misalnya di Amerika Serikat.
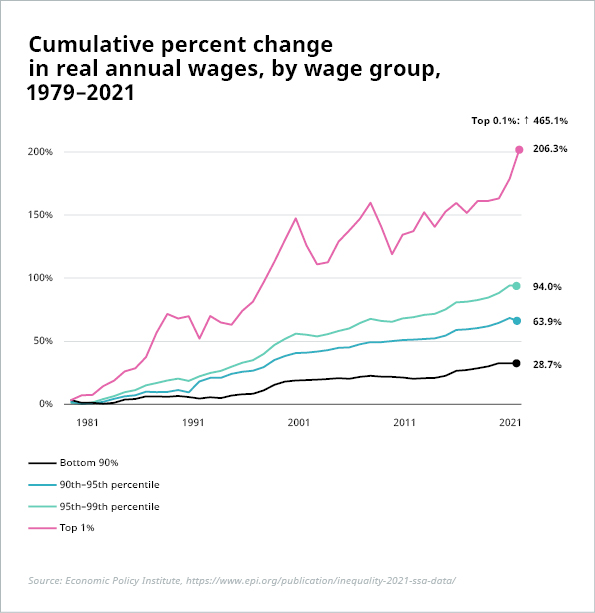
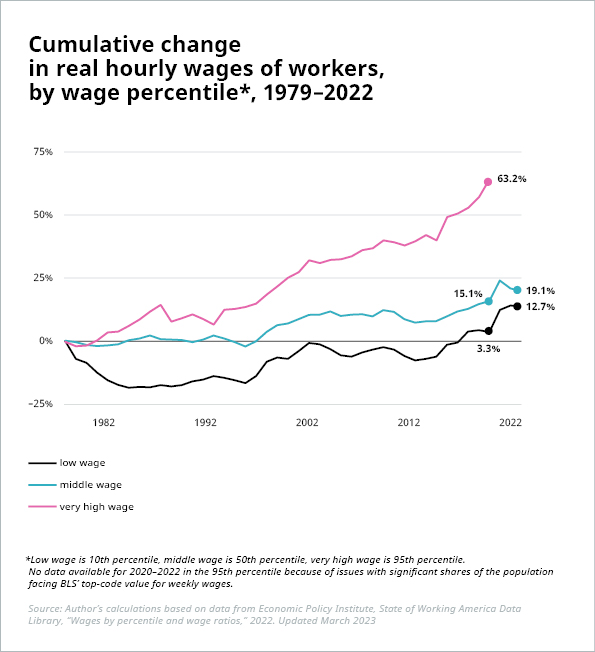
Sumber: Ilustrasi 1: Economic Policy Institute, https://www.epi.org/publication/inequality-2021-ssa-data/; Ilustrasi 2: Perhitungan penulis berdasarkan data dari Economic Policy Institute, State of Working America Data Library, “Upah berdasarkan persentil dan rasio upah,” 2022. Diperbaharui Maret 2023
*Upah rendah adalah persentil ke-10, upah menengah adalah persentil ke-50, upah sangat tinggi adalah persentil ke-95. Tidak ada data yang tersedia untuk tahun 2020–2022 pada persentil ke-95 karena adanya masalah dengan sebagian besar populasi yang menghadapi nilai kode teratas BLS untuk upah mingguan.
Tidak ada alasan untuk menganggap bahwa AI dan otomatisasi akan secara otomatis membuat kita menjadi lebih kaya sebagai masyarakat atau bahwa peningkatan kekayaan akan didistribusikan secara merata. Oleh karena itu, kita harus sama-sama siap menghadapi skenario yang lebih negatif dan mendiskusikan bagaimana cara mengurangi konsekuensinya. Misalnya, apakah proses AI dapat diperlakukan seperti tenaga kerja manusia? Jika ya, maka kita dapat mempertimbangkan untuk pengenaan pajak untuk mendukung redistribusi kekayaan atau untuk membiayai pelatihan atau tunjangan dan pensiun bagi para pekerja yang tergeser.
Selain itu, kita juga perlu mempertanyakan perkiraan perpindahan pekerjaan pada tingkat dasar. Siapa yang dapat dengan yakin menyatakan bahwa pekerjaan ini akan berkurang? Bagaimana kita bisa tahu jenis pekerjaan apa yang akan ada di masa depan? Tidak ada satu pun dari proyeksi ini yang benar-benar dapat diandalkan atau bersifat objektif – proyeksi ini terutama didasarkan pada pendapat sekelompok orang saja. Sebagai contoh, Laporan Masa Depan Pekerjaan WEF, salah satu laporan paling berpengaruh yang mengusung topik ini, didasarkan pada survei pemberi kerja. Namun, sangatlah naif jika kita berpikir bahwa siapa saja, apalagi seorang kader pemimpin perusahaan karbitan, dapat memiliki pemahaman yang begitu yakin dan pasti akan pekerjaan dan keterampilan apa saja yang dibutuhkan di masa depan. Semestinya kita tidak percaya begitu saja layaknya mempercayai sebuah ramalan. Hal ini membawa kita kembali pada prediksi kecanggihan mobil di awal abad ke-19, tren belanja jarak jauh di tahun 1960-an, penemuan ponsel di tahun 1980-an, atau komputer sejak tahun 1940-an. Begitu banyak prediksi teknologi yang telah keliru total – mengapa hal ini harus berubah sekarang? Namun, jenis ramalan bola kristal ini merupakan elemen kunci dalam perkiraan “masa depan pekerjaan”.
Faktanya, penelitian yang kuat secara ilmiah tentang topik ini masih sangat langka. Salah satu dari sedikit makalah di bidang ini mempelajari dampak AI pada pasar tenaga kerja di AS dari tahun 2007 hingga 2018. Para penulis (dari MIT, Princeton, dan Boston University) menemukan bahwa eksposur AI yang lebih besar dalam bisnis dikaitkan dengan tingkat perekrutan yang lebih rendah, yaitu setidaknya hingga saat ini, adopsi AI terkonsentrasi pada substitusi daripada penambahan pekerjaan. Makalah yang sama juga tidak menemukan bukti bahwa efek produktivitas yang besar dari AI akan meningkatkan perekrutan. Beberapa pihak mungkin menganggap bahwa pernyataan ini mendukung pandangan distopia. Namun, penting untuk dicatata bahwa penelitian ini berdasarkan pada data lowongan online, sehingga dengan demikian hasilnya harus diperlakukan secara hati-hati, seperti yang telah dijelaskan secara rinci di salah satu artikel kami. Selain itu, akibat dinamika inovasi dan adopsi teknologi, hampir tidak mungkin untuk mengekstrapolasi dan memproyeksikan temuan-temuan ini untuk membuat prediksi yang cukup meyakinkan bagi perkembangan di masa depan.
Selain itu, secara lebih filosofis, apa manfaat dari keberadaan manusia jika kita bekerja lebih sedikit? Bukankah kegiatan bekerja sudah menjadi hakikat kita; sebagai sifat alamiah manusia yang sesungguhnya.
Pertanyaannya adalah, sulit dan mudah bagi siapa? Beruntungnya, kita semua tidak memiliki keunggulan dan kelemahan yang sama, sehingga kita tidak menganggap tugas-tugas yang sama itu “mudah” dan “sulit”. Pernyataan ini hanyalah sebuah generalisasi yang didasarkan pada penilaian yang sepenuhnya subjektif. Dan jika itu benar, maka kebanyakan orang mungkin akan menganggap tugas-tugas yang repetitif biasanya dianggap mudah, atau setidaknya lebih mudah. Hal ini secara langsung bertentangan dengan klaim berikutnya, yaitu:
Forum Ekonomi Dunia atau WEF menyatakan bahwa AI akan mengotomatiskan tugas-tugas repetitif seperti entri data dan produksi lini perakitan, “memungkinkan pekerja untuk fokus pada tugas-tugas yang bernilai lebih tinggi dan memiliki daya tarik yang lebih tinggi” dengan “manfaat bagi bisnis dan individu yang akan memiliki lebih banyak waktu untuk berkreasi, berstrategi, dan berjiwa wirausaha.” BCG berbicara tentang “pergeseran dari pekerjaan dengan tugas-tugas yang repetitif di lini produksi ke bidang pemrograman dan pemeliharaan teknologi produksi” dan bagaimana “penghilangan tugas-tugas yang biasa dan repetitif di bidang hukum, akuntansi, administratif, dan profesi serupa membuka kemungkinan bagi karyawan untuk mengambil peran yang lebih strategis”. Pertanyaannya adalah, siapa yang diuntungkan dari hal ini? Tidak semua pekerja yang dapat melakukan tugas-tugas repetitif memiliki potensi untuk mengambil peran strategis, kreatif dan berwirausaha, atau memprogram dan memelihara teknologi produksi. Faktanya, tidak semua orang dapat dilatih untuk setiap peranan maupun jabatan tertentu. Tugas-tugas yang lebih menyenangkan dan menarik bagi para intelektual (seperti para pendukung masa depan pekerjaan yang lebih cerah berkat AI) mungkin terlalu menantang bagi pekerja yang cenderung tidak terlalu memiliki kecerdasan intelektual yang pekerjaannya – yang sebetulnya tergolong cukup memuaskan bagi mereka – baru saja diotomatisasi. Dan tidak semua pekerja kantoran bisa atau ingin menjadi pengusaha atau ahli strategi. Selain itu, apa sebenarnya arti dari “nilai yang lebih tinggi”? Siapa yang diuntungkan dari hal ini? Pekerjaan baru yang tercipta sejauh ini, seperti pekerja gudang Amazon, atau pengemudi Uber dan layanan pengiriman pos, tidak sepenuhnya memberikan upah yang layak dan terjamin. Terlebih sejak awal tahun 1970-an, perusahaan-perusahaan telah menunjukkan ketidaktertarikan mereka untuk berbagi nilai tambah dari peningkatan produktivitas dengan para pekerja:
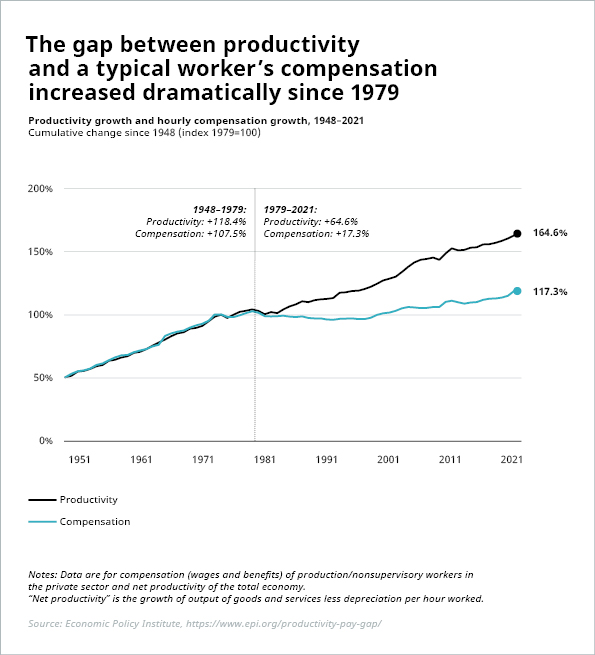
Sumber: Economic Policy Institute, https://www.epi.org/productivity-pay-gap/
Di sisi lain, sejumlah besar aplikasi AI yang ada telah melakukan tugas-tugas yang lebih tinggi tingkat kerumitannya hingga yang sangat terampil berdasarkan penggalian data, pengenalan pola, dan analisis data: diagnosis dan perawatan kondisi medis, chatbot layanan pelanggan, optimasi tanaman dan strategi pertanian, nasihat keuangan atau asuransi, pendeteksi kecurangan, penjadwalan dan perutean dalam logistik dan transportasi umum, riset pasar dan analisis perilaku, perencanaan tenaga kerja, desain produk, dan banyak lagi. Kemudian, ditambah lagi dengan beragam aplikasi ChatGPT. Dampak penuh dari aplikasi-aplikasi ini di pasar kerja masih belum begitu jelas, namun yang pasti, aplikasi-aplikasi ini lebih dari sekadar menggeser tugas-tugas yang biasa dan repetitif dari profil pekerjaan saja.
Meskipun tidak sepenuhnya setuju dengan pernyataan ini, namun hal ini sering kali dikemukakan sebagai solusi yang cukup sederhana untuk mempersiapkan diri menghadapi pergeseran pasar tenaga kerja di masa depan yang digerakkan oleh AI dan “merangkul manfaat sosial yang positif dari AI” (WEF). Faktanya, hal ini memiliki beberapa peringatan yang menjadikannya solusi yang jauh dari sederhana.
Pertama, tidak perlu menekankan kembali sebuah keniscayaan bahwa mustahil bagi kita untuk bisa memprediksi “masa depan pekerjaan” dengan tepat, terutama pekerjaan mana yang akan diminati dan mana yang tidak. Selain itu, berdasarkan dampak dari revolusi industri terdahulu dan penelitian saat ini, kemungkinan besar adopsi AI secara luas akan memperkenalkan pekerjaan baru dengan profil yang belum dapat kita antisipasi. Hal ini menunjukkan bahwa kita harus membekali para profesional masa kini dan di masa depan dengan keterampilan yang diperlukan untuk pekerjaan yang saat ini bahkan belum kita ketahui. Salah satu solusi yang lazim diusulkan untuk mengatasi masalah tersebut yaitu dengan mendorong pembelajaran jangka panjang dan mempromosikan bentuk pelatihan dan pendidikan yang lebih mudah diadaptasi dan berjangka pendek. Pilihan ini tentu saja menjadi valid dan semakin populer meskipun kemudian terdapat beberapa aspek yang perlu diingat. Misalnya, 15-20% populasi orang dewasa di Amerika Serikat dan Uni Eropa [2] memiliki kemampuan baca tulis yang rendah (PIAAC level 1 atau di bawahnya), yang berarti mereka memiliki masalah dengan tugas-tugas seperti mengisi formulir atau memahami teks mengenai topik yang tidak familiar. Bagaimana kandidat ini dapat dilatih untuk berhasil dalam “proyek yang lebih kompleks dan bermanfaat” jika mereka tidak dapat membaca buku teks, menavigasi manual, atau menulis laporan sederhana? Selain itu, sekitar 10% pekerja penuh waktu di AS dan Uni Eropa adalah pekerja miskin/working poor. [3] Kelompok individu semacam ini biasanya tidak memiliki cukup waktu, sumber daya, atau dukungan dari pemberi kerja untuk belajar sepanjang hayat dan dengan demikian tidak memiliki akses yang memadai untuk mendapatkan pelatihan yang efisien, tepat sasaran, dan terjangkau.
Ketika isu-isu tersebut dapat diatasi, banyak dari para pekerja tersebut mungkin sudah ketinggalan zaman. Pada tahun 2018, pengusaha AS memperkirakan bahwa lebih dari seperempat tenaga kerja mereka membutuhkan setidaknya tiga bulan pelatihan untuk mengimbangi persyaratan keterampilan yang diperlukan untuk tugas mereka saat ini pada tahun 2022. [4] Dua tahun kemudian, persentase tersebut meningkat dua kali lipat menjadi lebih dari 60%, dan jumlahnya serupa di seluruh dunia. [5] Selain itu, bahkan sebelum periode pasca-Resesi Besar, hanya sekitar 6 dari 10 pekerja AS yang menganggur yang berhasil dipekerjakan kembali dalam waktu 12 bulan pada periode 2000 hingga 2006. [6] Pada tahun 2019, angka ini setara dengan apa yang terjadi di Uni Eropa. [7] Seiring dengan perubahan yang semakin cepat terkait kebutuhan keterampilan, ditambah dengan kurangnya waktu dan/atau sumber daya untuk kelompok rentan seperti pekerja miskin dan pekerja dengan tingkat literasi yang rendah, belum lagi kurangnya jaring pengaman dan langkah-langkah yang ditargetkan dalam sistem pengembangan tenaga kerja yang kekurangan dana, prospek para pekerja tersebut tidak tampak akan membaik dalam waktu dekat.
Selain itu, pandemi secara masif telah mengakselerasi adopsi otomatisasi dan AI di tempat kerja di berbagai sektor. Robot, mesin, dan sistem AI telah digunakan untuk membersihkan lantai, mengukur suhu atau memesan makanan, menggantikan karyawan di tempat makan, loket tol, atau pusat panggilan, berpatroli di real estat yang kosong, meningkatkan produksi industri persediaan rumah sakit, dan masih banyak lagi dalam waktu yang teramat singkat. Dahulu, teknologi baru diterapkan secara bertahap, memberikan cukup waktu bagi karyawan untuk bertransisi ke peran dan tugas mereka yang baru. Kali ini, para pemberi kerja bergegas mengganti pekerja dengan mesin atau perangkat lunak karena adanya aturan lockdown atau pembatasan sosial yang tiba-tiba. Hal ini merupakan perbedaan penting dari revolusi industri yang terjadi sebelumnya dengan apa yang baru-baru ini terjadi. Banyak pekerja yang diberhentikan tanpa cukup waktu untuk berlatih kembali. Peristiwa yang sama mungkin akan terjadi di masa depan – baik itu pandemi lain atau terobosan teknologi – dan sebagai masyarakat, kita harus siap menghadapi peristiwa ini dan memberikan dukungan yang cepat, efisien, dan yang terpenting, realistis terhadap para pekerja yang terdampak.
Jika sebuah perusahaan mengganti semua kasirnya dengan robot, mengapa perusahaan tersebut ingin melatih ulang para pekerja baru yang redundan? Bahkan pemerintah pun mengalami kesulitan untuk mengambil sikap ini dalam hal pelatihan dan pendidikan. Banyak negara yang berfokus pada pendidikan tinggi atau pelatihan lain untuk pekerja muda daripada melatih ulang para pencari kerja atau karyawan. Sebagai contoh, pemerintah AS menghabiskan 0,1% dari PDB untuk membantu para pekerja melewati masa transisi pekerjaan, kurang dari setengah dari yang dihabiskan 30 tahun yang lalu – meskipun tuntutan keterampilan berubah jauh lebih cepat dibandingkan dengan tiga dekade yang lalu. Dan sebagian besar bisnis terutama tertarik untuk memaksimalkan keuntungan – begitulah cara kerja ekonomi kita. Perlu diingat bahwa kita hidup di dunia dimana bahkan seorang penjual makanan dan penjaga hewan peliharaan pun bisa dipaksa oleh majikannya untuk menandatangani perjanjian non-kompetisi agar mereka tidak mendapatkan kenaikan gaji dengan mengancam akan pindah ke pesaing yang memberikan gaji yang lebih tinggi.
Perangkat lunak percakapan atau chatbot yang berkinerja baik dapat menawarkan layanan pusat panggilan yang berkapasitas 1.000 orang bagi perusahaan yang hanya perlu mempekerjakan 100 personel. Dengan demikian, bot dapat merespons 10.000 pertanyaan dalam satu jam, jauh lebih tinggi daripada volume realistis yang dapat ditangani oleh petugas call center yang paling efisien sekalipun. Selain itu, chatbot tidak pernah sakit, tidak membutuhkan cuti, atau meminta tunjangan dan keuntungan. Mereka membuat keputusan yang konsisten dan berdasarkan bukti serta tidak mencuri atau membohongi atasan mereka. Jadi, jika kualitas perangkat lunak ini memadai dengan nilai yang terjangkau, mungkin akan memicu perdebatan di antara para pemegang saham jika sebuah perusahaan menyia-nyiakan tawaran ini. Bagaimanapun juga, solusi yang meningkatkan efisiensi dan produktivitas sekaligus menurunkan biaya adalah sebuah impian yang menjadi nyata bagi perusahaan. Jadi, jika perusahaan tidak melewatkannya maka kompetitornya yang akan mengambil kesempatan ini. Dan terlepas dari propaganda “teknologi untuk kebaikan sosial” yang selalu kita dengar dari Silicon Valley, sebagian besar perusahaan sebetulnya tidak begitu peduli dengan nasib para pekerja yang akan segera pensiun di masa mendatang.
Pada prinsipnya, kita tidak semestinya mendramatisir atau berupaya keras meyakinkan diri sendiri bahwa akan ada cukup banyak lapangan pekerjaan bagi kita, atau kita akan terus mengejar ketertinggalan. Sebagian besar masalah atau solusi yang sering dikemukakan cenderung dibahas secara terbatas di dalam gelembung akademis atau gelembung para peneliti, pengusaha teknologi, dan pembuat kebijakan tingkat tinggi, yang tercampuraduk dalam sejumlah idealisme substantif. Namun, untuk dapat mengikuti perkembangan – baik maupun buruk – yang berpotensi besar dalam mengubah pasar tenaga kerja dan masyarakat secara menyeluruh, kita perlu melihat jauh ke depan dan merancang strategi yang realistis untuk masa depan berdasarkan fakta dan data yang objektif.
[1] https://stats.oecd.org/Index.aspx?DatasetCode=LFS_SEXAGE_I_R#
[2] US: https://www.libraryjournal.com/?detailStory=How-Serious-Is-Americas-Literacy-Problem
EU: http://www.eli-net.eu/fileadmin/ELINET/Redaktion/Factsheet-Literacy_in_Europe-A4.pdf
[3] US: https://nationalequityatlas.org/indicators/Working_poor?breakdown=by-race-ethnicity&workst01=1
EU: https://ec.europa.eu/eurostat/databrowser/view/sdg_01_41/default/table?lang=en
[4] The Future of Jobs Report 2018, World Economic Forum, 2018.
[5] The Future of Jobs Report 2020, World Economic Forum, 2020.
[6] Back to Work: United States: Improving the Re-employment Prospects of Displaced Workers, OECD, 2016.

Tulisan ini merupakan artikel ketiga dari rangkaian tulisan tentang pembelajaran mesin dalam teknologi SDM. Jika Anda belum membacanya, kami sarankan Anda untuk membaca dua tulisan sebelumnya: bagian 1 dan bagian 2.
Dalam dua tulisan terakhir, kita membahas kebutuhan ahli domain dalam membangun grafik pengetahuan untuk mesin pencocokan pekerjaan serta masalah yang ingin kita selesaikan pada tingkat konseptual. Dalam tulisan ini, we’re going to delve into the challenges of building a job matching system on a more technical level. (Don’t worry, it’s not going to get too technical – or at least not for long…) We will again focus on a job matching system as an example, but the basic ideas are relevant to many different applications in HR tech.
Based on the discussion in the last post, the goal of our system is to input raw, unstructured data like resumes and job descriptions, process the data fairly and accurately to output the best matches, and explain the results truthfully. For sake of argument, let’s say we’re matching candidates to a job. We won’t discuss potential graphical elements in resumes, say skill levels or section headers, because that’s a huge challenge in and of itself (which, by the way, we’ve recently solved here at JANZZ). Instead, we’ll focus on input data in the form of text.
In the broadest sense, there are two approaches we can take:
Tabular data is generally not considered avant-garde, but AI-based text processing is hugely popular (pretty much anyone not living under a rock has heard of NLP, GPT-3 or conversational AI). This may be at least part of why the first approach is by far the most common in HR tech: You get to throw out all those fancy words when marketing your products – NLP, deep learning, cutting-edge, yadda yadda. So let’s try and build a matching engine like this.
If you want to perform matching on text data, your system has to deal with actual words. Since digital systems are designed to deal with digits, this means the words have to be translated into digits in some way that is meaningful to the machine. The document text must be turned into an array, or vector, of numbers. In the simplest version, you have a dictionary of all possible words in your resume/job description universe, and a formula that assigns a number to each word in the dictionary based on the document at hand. This could be, for instance, a count of how often the word appears in the document, multiplied with some weight based on relevance or other criteria. So for each document, you get an array (vector) with as many slots (components) as there are words in your dictionary, filled with numbers according to that formula. If, in addition, you want to somehow encode context to better capture the meaning of these words, you might extend your dictionary to include certain sequences of words as well.
Whether you include context or not, a significant challenge of this technique is the sheer number of potential words or phrases that candidates and recruiters can put in their resumes and job descriptions. For instance, there are tens of thousands of standardized skills in collections like ESCO or LinkedIn. And real-life people don’t just use standardized terms. So just for skills, you’ll end up with millions of different expressions, many of which are related to each other to varying degrees. And because the number of expressions corresponds to the number of components in the vectors representing the documents, you end up with huge vectors for each document, causing significant computational challenges down the road. So somehow or other, this complexity needs to be reduced, i.e., we want to condense the information contained in the documents into smaller vectors – but without losing the underlying semantics. This inevitably leads to embeddings; where complex models based on deep neural networks typically perform significantly better than simple models. In this approach, the model decides, based on its training data, how to transform candidate and job profiles into much smaller vectors that live a vector space (think points with coordinates labeling their positions in a three-dimensional space) in such a way that vectors representing similar profiles are close to each other. If you then feed it new profiles, it can embed them in the same way and just look for the ones that are closest together (nearest neighbors). Sounds fairly straightforward, right? Well, it’s not.
For our purposes, one of the key issues with embeddings (and, by the way, with neural networks in general) is their lack of interpretability: the components of the vectors no longer individually correspond to semantic concepts or other directly interpretable distinctions. There have been multiple attempts in the scientific community to address this issue. So far, however, the proposed approaches have proven computationally impractical, resulted in poor performance, or shown very little improvement in interpretability. This means that there is no way of knowing for certain which criteria the system used to determine similarity between two profiles. Instead, we have to make do with post-hoc explanations using additional methods. But all these methods do is perform yet more statistics to determine the most likely explanations for the system’s behavior. And, as studies have determined, different explanation methods often disagree in terms of the resulting explanations, showing that they rarely produce truthful insight into the decisions made by the system. In fact, to quote one study: “The higher the model complexity, the more difficult it may be for different explanation methods to generate the true explanation and the more likely it may be for different explanation methods to generate differently false explanations, leading to stronger disagreement among explanation methods.” This could become a serious liability concern in the not-too-distant future. Or this phenomenon could be exploited to avoid liability. As it turns out, explanation techniques can easily be abused for fair washing, ethics washing, white box washing, or whatever you want to call it. For instance, this study demonstrates that decisions taken by an unfair black-box model can be systematically rationalized through an explanation tool that provides seemingly fair explanations with high fidelity to the black-box model.
On top of that, no matter what modeling method you use, and what explanation method: If you ask why a particular output corresponds to a particular input, the answer depends not only on the mechanics of the particular method, but also very significantly on the distribution of the training set. Which leads us to the next point.
We are asking this system to understand similarity of expressions (e.g. synonyms, near-synonyms), of the underlying concepts (e.g. similar skills, job titles, certifications, and so on), and of the complete profiles. On the level of expressions and concepts, we can certainly use our knowledge graph, which – after reading the first post in this series – we built and curate with domain experts. But for the actual matching, our ML model needs vast amounts of high-quality data to learn the similarities between profiles. Of course, when you hear the vast numbers of resumes or job postings certain providers claim to process, you immediately think there’s ample job-related big data out there to feed into our system. But that’s like saying there are countless images on the internet so you can easily train a system to recognize images of, well, everything. In image recognition, it is well understood that a model that recognizes images of poodles cannot easily be retrained to recognize Venezuelan Poodle moths – even though they do share some similarities…

The same is true for job or skill similarity. Just like the universe of images, the labor market domain is very heterogeneous. What makes two jobs similar in one case does not necessarily transfer to another. Instead, you need a large amount of data covering similarities in each one of many different areas including niche careers such as ocularists and hippotherapists (if you don’t know what these people do, that’s exactly the point). Because this niche data simply doesn’t exist in the quantity this system needs, we have to find a way to work around this issue. And there are, of course, techniques to deal with small datasets, but they are not easy to implement, and maintaining high quality of data to achieve good results is challenging with any of the current techniques. This is a key reason most job matching systems on the market perform more or less ok when matching software engineers to roles, but fail miserably for occupations with less online coverage, or where the coverage is asymmetric between job postings and online candidate profiles, like blue collar workers in waste management.
In addition, labor markets continuously evolve, even dramatic shifts can happen very quickly on multiple levels, new occupations, new employers, new educations emerge all the time, certain skills become irrelevant, other become more important. These dynamics can cause models to go stale quickly, requiring frequent retraining to maintain performance. This requires not only an endless supply of fresh training data, with all the challenges that entails, and countless hours of highly paid work, but, due to the GPU-hungry processes involved, also comes with a significant carbon footprint.
We set out to build a system that produces fair and accurate results with truthful explanations. But so far, we can’t be sure our system can provide truthful explanations, or that we can continuously feed our hungry system with enough high-quality training data to produce fair and accurate results in all professional fields—at least not without burning through the budget and the planet at a painfully high rate. And then Molnar, author of the highly influential book Interpretable Machine Learning, tells you that in fact, when dealing with small datasets, interpretable models with good assumptions often perform better than black-box models.
Tabular data may not sound very exciting, but it comes with an interesting feature: For tabular data, deep learning models generally do not perform better than simple models.[1] In other words, there are simple models that are at least as accurate as your highly complex, state-of-the-art model. And, unlike a complex model, any one of these simple models can be designed to be interpretable. Of course, we still have the challenge of obtaining and preparing high-quality training data and securing the right people for quality assurance, localization, and so on. The challenges are very similar to those for knowledge graphs discussed in the first post of this series. But at least we can eliminate the issue of unreliable explanations and easily identify and correct any bias. We could, by the way, also just build similarity into our human-curated knowledge graph and skip ML in the matching step altogether. Either way, this leaves us with the – by no means simple – problem of parsing and normalizing raw text data.
Without getting too deep into the weeds, parsing and normalizing text data is a language-based problem that requires a large amount of very careful training and a knowledge graph. With the right combination of natural language processing/deep learning models we can certainly build a powerful parser – provided we can feed it with carefully curated gold-standard training sets.
As for normalization, we need it, and we need high performance: Without good normalization, our matching system will produce less accurate results. For instance, by weeding out good candidates for using terms that even only slightly differ from those in the job description, or by giving higher weight to skills that are written in several different ways within both of the documents. Here’s a real-life example of failed normalization:
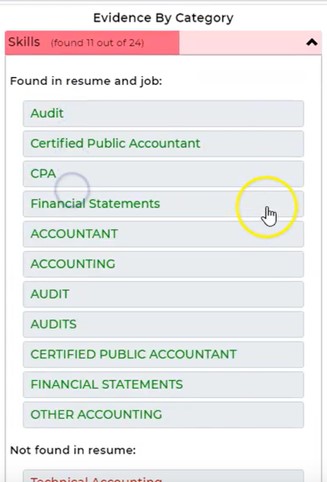
Because the terms “Audit”, “AUDIT” and “AUDITS” are not recognized as the same concept, the weight of this single skill is tripled. In fact, the eleven skills the system claims to have recognized in both the job description and the resume actually only comprise three to four distinct concepts. And even if we made our parser case-insensitive (which, clearly, any decent parser should be), it would not be able to equate the expressions “Certified Public Accountant” and “CPA”. If we now had another candidate who had ten distinct skills matching the job description, that person may rank lower than this candidate. (As a side note, “financial statements” is not a skill. Is this someone who can prepare financial statements? Or audit them? Maybe just read them?)
Of course, if we want to perform normalization, we need something to normalize the terms against. Which is where our knowledge graph comes in. And the better and more extensive the knowledge graph is, the better the normalization. By the way, the vendor from this example claims to provide the most accurate parser in the industry. So much for marketing claims. They also claim to perform knowledge graph-based normalization. Then again, their knowledge graph is built with ML…
So, what have we learnt? When it comes to job matching, complex approaches using the latest ML techniques are not necessarily a good choice. They may be more exciting in terms of marketing, but given the explainability issues, data challenges and – most importantly – the poor results, they are by no means worth the time, money or effort required. A much more promising approach may be to keep the matching step simple and instead focus on accurately processing the input data. For instance, by building a world-class parser using deep tech and gold-standard training sets – i.e., annotated by people who understand the content and context of the data – combined with a knowledge graph built and curated by people who – you guessed it – understand the content and context of the knowledge modeled by the graph. So you still get to play with cutting-edge machine learning and data science tech. But you also get to broaden your horizon and work with people who know about something other than data science and machine learning. And it will lead to better results. Not just “statistically significant single-digit percentage improvements” because, let’s be honest, single digit improvements on appalling is still far from great.
As 2022 comes to a close, maybe it’s time to reflect on how much money and effort has been spent and how little has been achieved since we first started out. And ask yourself if the time has finally come to bid farewell to the mythical beast you have been pursuing for so long.
May 2023 bring you new beginnings.
[1] See, for example: Rudin, Cynthia, Chaofan Chen, Zhi Chen, Haiyang Huang, Lesia Semenova, and Chudi Zhong. “Interpretable machine learning: Fundamental principles and 10 grand challenges.” Statist. Surv. 16 (2022): 1-85 and Shwartz-Ziv, Ravid, and Amitai Armon. “Tabular data: Deep learning is not all you need.” Information Fusion 81 (2022): 84-90.

“Jika saya punya waktu satu jam untuk memecahkan masalah, saya akan menghabiskan 55 menit untuk memikirkan masalahnya dan lima menit untuk memikirkan solusinya.” – Albert Einstein
Artikel ini merupakan bagian kedua dari rangkaian artikel tentang pembelajaran mesin dalam teknologi SDM. Jika Anda belum membacanya, kami sarankan Anda untuk membaca tulisan pertama di sini.
Di artikel terakhir, kami menjelaskan mengapa dibutuhkan lebih dari sekedar ilmu data dan Machine Learning (ML) untuk membangun grafik pengetahuan dalam sistem pencocokan pekerjaan. In a nutshell, to build a knowledge representation of sufficient quality, you need people who understand the knowledge you want to represent. More generally, if you want to solve a problem as opposed to putting out fires, you need people who understand the problem (and not firefighters). This is key not only to determining a good approach, but to the entire system lifecycle. So many attempts at innovative problem-solving fall flat because a) they target the wrong problem or b) the people involved did not understand the problem. So, before we get into the nitty-gritty of ML-based HR tech in the next post, let’s discuss the problem we want to solve, starting with the all-important results.
The jobs
The discussion that follows is based around a job matching system as an example of HR tech. However, this discussion is highly relevant to any kind of HR analytics.
In a job matching system, at the most superficial level, you want to feed candidate and job profiles into a machine, let the machine do its magic and spit out a list of… well, depending on the problem you want to solve, it could be:
A significant part of understanding the problem is defining similarity. What makes one job similar to another? A first idea might be that two jobs are similar if they have similar or even the same job titles. So, when are job titles similar? Take a look at the following examples:
The job titles on the right all share the keyword Manager, but they are clearly not similar in any respect. On the other hand, most of the job titles on the right are similar in some sense. However, whether they are close enough depends on the problem you want to solve, and where the expressions came from. For instance, if you want to use the results of your system for, say, national statistics, these job titles may be close enough. If you want to recommend jobs to a software engineer, that person may not be interested in any of the other jobs, as they only cover a subset of the tasks and skills of a software engineer – in theory. In reality, you will find that the terms software engineer, software developer and software programmer are often confused or used interchangeably in job postings. In addition, even identical job titles often refer to very different jobs: an accountant for a global conglomerate is not the same as an accountant for a small local business; a project manager in the manufacturing department may not perform well if transferred to the marketing department; a carpenter with 18 months of training is probably not as skilled as a carpenter with 4 years of training. Business size, industry, training and many other factors all impact the skill set required or acquired in a given position. So let’s consider jobs in terms of skills.
The skills
We discussed skills in quite some detail in this post. The gist of it is that first of all, there is a lot of talk about skills, but no consensus on the most basic and pertinent question, namely what exactly constitutes a skill, i.e. the definition. Then there is the question of granularity, i.e. how much detail should be captured. The choice is highly dependent on the problem you want to solve. However, your system will typically need to understand skills at the finest level of granularity in any case so that it can correctly normalize any term it encounters to whatever level of detail you settle on. Which leads to the final point: When it comes to skills, we have a highly unfavorable circumstance of projection bias in a tower of babel. Given a term or expression describing a skill, most of us expect that everyone means the same thing when they use that term. In reality, there is significant confusion because everyone has their own interpretation based on their unique combination of experience, knowledge and other factors. We also discussed this in an episode of our podcast: Analyzing skills data. Long story short: There is much work to do in terms of skills and skills modeling.
Now, in an ideal world everyone would speak the same skills language. Realistically, this is simply not going to happen. What we can do is attempt to integrate this translation work within our system. Which is one of the key strengths of a knowledge representation. And we discussed in the last post of this series at length why a good knowledge graph cannot be generated by a system purely based on ML. So let’s suppose for a moment we have a solid definition of skills, the appropriate level of granularity for our problem and we are all talking about the same thing.
Again, we want to find a workable definition of similarity. Working with the premise that a job is determined by its skill set, if you have two jobs with the same skills, then the jobs are the same. This implies that the more skills two jobs have in common, the more similar the jobs. At the other end of the spectrum, two jobs that have no skills in common are not similar. Sound’s logical, right? So, if we feed lots of job postings into our system to analyze them all in terms of skills, our system can identify similar jobs. Easy. Let’s look at an example. The following are all required skills listed in three real-life job postings:
According to our theory – and with an understanding that certain terms have similar meanings, like client centered and guest focus – jobs A and B must be similar and job C quite different. Think again.
Ok, but surely our system will discern more accurate and comparable skill sets if we feed it more data. Well, it might – if your system processes that data correctly. So far, these systems typically deliver results like the ones discussed in this post, where 1 in 15 online job postings for refuse workers in Europe apparently require knowledge in fine arts.
The more pertinent question, however, is how useful that would be to the problem you want to solve. As we have explained before, there is no such thing as a standard skill set for a given profession in a global sense. In addition, standardizing skills sets according to job titles is more or less equivalent to simply comparing job titles. So, if you have a matching or recommendation system, this approach will not be helpful. If you want to perform skills analysis, say, to develop a skills strategy for your business, it will not be helpful either. Instead, we need to come up with a viable definition of job similarity that not only consists of a set of features like job titles, skills, industries, company size, experience, education, and so on. The definition must also include aspects such as the importance of each feature depending on the context. For instance, specific training and certification is an indispensable feature of jobs for registered nurses and irrelevant for stocking and unloading jobs at a supermarket. Work experience is not helpful in matching graduates to entry-level jobs, but likely necessary when looking or hiring for a management position. Of course, if you’re designing a purely ML-based system, you probably want to leave the task of determining importance or weighting of the features to the system. However, somewhere along the line, you will (hopefully) want someone to check the results. And it shouldn’t be a data scientist.
The system
Suppose you have found a workable definition of job similarity and you have a good knowledge graph to help your system understand all the different terms used in your job-related data. Now you want to build a matching engine based on ML. Again, you need to first think about the problem at hand. Apart from the semantic aspects discussed above, there are ethical considerations. One thing you will want to avoid for obvious reasons is bias – in any use case. Also, if you want the system to be used in any part of an HR tech stack, it must be both explainable and interpretable. For one thing, there is increasing evidence that legislation will eventually dictate explainability and interpretability in ML-based HR tech (AI Bill of Rights, EU AI Act, Canada’s AIDA, and so on). Arguably more important is the fact that HR tech is used in decisions that strongly affect real people’s lives and as such, must be transparent, fair and in all respects ethical. And even if your system is only going to produce job recommendations for users, explainable results could be an excellent value proposition by building trust and providing users with actionable insights. And with any HR analytics tool, you should want to know how the tool arrived at its decision or recommendation before acting on it. But first, we need to discuss what exactly we mean by interpretability and explainability in an ML-based system, and how the two differ.
These terms are often used interchangeably, and the difference between the two is not always clear. In short, an ML system is interpretable if a human can understand exactly how the model is generating results. For instance, a matching engine is interpretable if the designers know how the various features (job titles, skills, experience, etc.) and their weights determine the match results. An explainable ML system can tell humans why it generated a specific result. The difference is subtle, but key. Think of it like this: Just because the system told you why it did something (and the explanation sounds reasonable), that doesn’t mean that you know why it did it.
In our matching engine example, an explainable system will provide a written explanation giving some insight into what went into the decision-making process. You can see, say, a candidate’s strengths and weaknesses, which is certainly helpful for some use cases. But you don’t know exactly how this information played into the matching score and thus you cannot reproduce the result yourself. In fact, depending on how the system is designed, you can’t even be sure that the explanation given really matches the actual reasoning of the system. It is also unclear whether the explanation accounts for all factors that went into the decision. There could be hidden bias or other problematic features. Apart from the fact that these issues could cause difficulties in a legal dispute, it looks a lot like transparency washing—particularly because most people are unaware of the potential inaccuracy of these explanations.
In an interpretable system, you know precisely how the results are generated. They are reproducible and consistent, as well as accurately explainable. In addition, it is easier to identify and correct bias and build trust. Simply put, an interpretable ML system can easily be made ethical by design.
However, even in an interpretable system you still face the challenge of correctly processing the data. It doesn’t really matter what color the box is, black, white or any other color under the sun. It’s still opaque if your system can’t properly deal with the input data. Because mistakes in the processing inevitably lead to spurious reasoning. To perform any kind of reliable analysis, your system must – at the very least – be able recognize and normalize the relevant information in a dataset correctly. Otherwise, we just end up back where we started:

Of course, no system is perfect, so the question is how much trash are you willing to accept? In other words, you need benchmarks and metrics. You need experts that are actually capable of evaluating the system and the results. And maybe let’s not set those benchmarks too low. After all, being better than appalling isn’t saying much…
As a fan of ML and data science (which, by the way, we are too – as long as it’s put to good use), you may still want to build a purely ML-based machine that can correctly process the data, feed it into an interpretable system and produce fair and accurate results with truthful explanations that can be understood by humans. So, in the next post, we’re going to dive into the nuts and bolts of this ML-based machine, looking at everything from training data over natural language processing and vector embeddings to bias mitigation, interpretability and explainability. Stay tuned.
Banyak mesin pencocokan dan rekomendasi pekerjaan yang saat ini ada di pasaran didasarkan pada Machine Learning (ML) dan dipromosikan sebagai revolusi teknologi SDM. Namun, terlepas dari semua upaya yang dilakukan untuk meningkatkan model, pendekatan, dan data selama dekade terakhir, hasilnya masih jauh dari apa yang diharapkan oleh pengguna, pengembang, dan ilmuwan data. Namun, konsensus yang ada tampaknya menunjukkan bahwa jika kita mendapatkan lebih banyak lagi data dan model yang lebih baik, serta meluangkan lebih banyak waktu, money and data scientists at the problem, we will solve it with machine learning. This may be true, but there is also ample reason to at least think about trying a different strategy. A lot of very clever people having been working very hard for many years to get this approach to work, and the results are – let’s face it – still really bad. In this series of posts, we are going to shed some light on some of the pitfalls of this approach that may explain the lack of significant improvement in recent years.
One of the key aspects that many experts have come to realize is that because job and skills data is so complex, ML-based systems need to be fed with some form of knowledge representation, typically a knowledge graph. The idea is that this will help the ML models better understand all the different terms used for job titles, skills, trainings and other job-related concepts, as well as the intricate relationships between them. With a better understanding, the model can then provide more accurate job or candidate recommendations. So far, so good. So the data scientists and developers are tasked with working out how to generate this knowledge graph. If you put a group of ML experts in a room and ask them to come up with a way to create a highly complex, interconnected system of machine-readable data, what do you think their approach will be? That’s right. Solve it with ML. Get as much data as you can and a model to work it all out. However, there are multiple critical issues with this approach. In this post, we’ll focus on two of these concerns that come into play right from the start: you need the right data, and you need the right experts.
ML uses algorithms to find patterns in datasets. To discern patterns, you need to have enough data. And to find patterns in the data that more or less reflect reality, you need data that more or less reflects reality. In other words, ML can only solve problems if there is enough data of good quality and an appropriate level of granularity; and the harder the problem, the more data your system will need. Generating a knowledge graph for jobs and associated skills with ML techniques is a hard problem, which means you need a lot of data. Most of this data is only available in unstructured and highly heterogeneous documents and datasets like free text job descriptions, worker profiles, resumes, training curricula, and so on. These documents are full of unstandardized or specialist terms, synonyms and acronyms, descriptive language, or even graphical representations. There are ambiguous or vague terms, different notions of skills, jobs, and educations. And there is a vast amount of highly relevant implicit information like the skills and experience derived from 3 years in a certain position at a certain company. All this is supposed to be fed into an ML system which can accurately parse, structure and standardize all relevant information as well as identify all the relevant relationships to create the knowledge graph.
Parsing and standardizing this data is already an incredibly challenging task, which we’ll discuss in another post. For now, let’s suppose you know how to build this system. No matter how you design it, because it’s based on ML to solve a complex task, it’s going to need a lot of data on each concept you want to cover in your knowledge graph. Data on the concept itself and on its larger context. For instance, it will need a large amount of data to learn that data scientists, data ninjas and data engineers are closely related, but UX designers, fashion designers and architectural designers are not. Or that CPA is an abbreviation of Certified Public Accountant, which has nothing in common with a CPD tech in a hospital.
This may be feasible for many common white-collar jobs like data scientists and social media experts, because their respective job markets are large and digitalized. But how much data do you think is out there for cleaner/spotters, hippotherapists or flavorists? You can only solve a problem with ML that you have enough data for.
Let’s suppose (against all odds) that you solved the data problem. You can now choose one of three possible approaches:
Based on what’s currently on the market, one wonders if most knowledge graphs in HR tech are built on the eyes wide shut approach. We have covered the results of several such systems in previous posts (e.g., here, here and here). You may also have come across recommendations like the ones below yourself.
If not, it may be that the humans involved in the process are all data scientists and machine learning experts, i.e., people who know all about building the system itself, instead of domain experts who know all about what the system is supposed to produce. Whether you fine tune the results at the end or give the system input or feedback along the way, at some point, you will have to deal with domain questions like the difference between a cleaner/spotter and a (yard) spotter, what exactly a community wizard is, or whether a forging operator can work as an upset operator. And then of course, all the associated skills. If you want a job matching engine to produce useful results, this is the kind of information your knowledge graph needs to encode. Otherwise you just perpetuate what’s been going on so far, namely:
You simply cannot expect data scientists to assess the quality of this kind of knowledge representation. Like IKEA said at the KGC in New York: domain knowledge takes years of experience to accumulate—it’s much easier to learn how to curate a knowledge graph. And IKEA is “just” talking about their company-specific knowledge, not domain knowledge in a vast number of different industries, different specialties, different company vocabularies, and so on. You need an entire team of domain experts from all kinds of different fields and specialties to assess and correct a knowledge graph of this magnitude and depth.
Finally, what if you want a knowledge graph that can be used for job matching in several languages? Again, an ML expert may think there’s a model or a database for that. Let’s look at databases first. Probably one of the most extensive multilingual databases for job and skills terminology is the ESCO taxonomy. However, apart from not being complete, it is riddled with mistakes. For instance, one of the skills listed for a tanning consultant is (knowledge of) tanning processes. Sound good, right? However, if you look at the definitions or the classification numbers for these two concepts, you see that a tanning consultant typically works in a tanning salon while tanning processes have to do with manufacturing leather products. There are many, many more examples like this in ESCO. Do you really want to feed this into your system? Maybe not. What about machine translation? One of the best ML-based translators around is DeepL. According to DeepL, the German translation of yard spotter is Hofbeobachter. If you have very basic knowledge of German, this may seem correct because Hof = yard and Beobachter = spotter. But Hofbeobachter is actually the German term for a royal correspondent, a journalist who specializes in reporting on royalty. A yard spotter, or a spotter, is someone who typically moves or directs, checks and maintains materials or equipment in a yard, dock or warehouse. The correct German term would be Einweiser, which translates to instructor or usher in DeepL. There is a simple explanation for these faulty translations: there is just not enough data connecting the German and English terms in this specific context. So, you need an entire team of multilingual domain experts from different fields and specialties to assess and correct these translations – or just do the translations by hand. And simply translating isn’t enough. You need to localize the content. Someone has to make sure that your knowledge graph contains the information that a carpenter in a DACH country has very different qualifications to a carpenter in the US. Or that Colombia and Peru use the same expressions for very different levels of education. Again, this is not a task for a data scientist. Hire domain experts and teach them how to curate a knowledge graph.
Of course, you can carry on pursuing a pure ML/data science strategy for your HR Tech solutions and applications if you insist. But – at the risk of sounding like a broken record – a lot of very smart people having been working on this for many years with generous budgets and no matter how hard the marketing department sings its praise, the results are still appalling. Anyone with a good sense of business should realize that it’s time to leave the party. If you’re still not convinced, keep an eye out for our next few posts in this series. We’re going to take down this mythical ML system piece by piece and model by model and show you: if you want good results anytime soon, you’ll need more than just data science and machine learning.