AI, otomatisasi, dan masa depan pekerjaan – beyond the usual bubbles
Dalam beberapa tahun terakhir, terdapat sejumlah banyak tulisan, artikel, dan laporan tentang bagaimana AI dan otomasi akan membentuk masa depan pekerjaan. Tergantung dengan perspektif atau agenda para penulisnya, tulisan-tulisan tersebut biasanya mengarah pada salah satu dari dua cara berikut ini: apakah teknologi baru akan mengancam pekerjaan dan memiliki dampak buruk terhadap pasar tenaga kerja, atau justru akan menciptakan masa depan yang lebih baik dan lebih cerah bagi semua orang dengan mengeliminasi pekerjaan-pekerjaan yang monoton dan menghasilkan ragam pekerjaan yang lebih baik dan lebih menarik? ChatGPT, sebagai contohnya, telah memicu antusiasme yang cukup menghebohkan dunia maya, berayun layaknya pendulum di antara dua pendapat yang sangat berbeda. Di satu sisi, ada banyak sekali tanggapan euforia, dengan banyaknya orang yang berandai-andai tentang bagaimana teknologi yang konon sangat cerdas ini dapat dimanfaatkan untuk meningkatkan kinerja kita – mulai dari jurnalisme, pengodean, analisis data, hingga manajemen proyek dan mengerjakan tugas-tugas sekolah. Di sisi lain, banyak yang menyuarakan kekhawatiran tentang potensi tindak penyalahgunaan, termasuk kemampuan ChatGPT menulis kode malware dan e-mail phishing, menyebarkan informasi yang salah, mengungkapkan informasi pribadi, dan menggantikan peran manusia di tempat kerja. Dalam artikel ini, kami ingin mencoba mengambil pandangan yang lebih bernuansa dengan membahas argumen dan klaim yang paling umum dan membandingkannya dengan fakta yang ada. Namun sebelum kita mulai membahas hal ini, mari kita jelaskan terlebih dahulu apa itu transformasi digital yang digerakkan oleh AI. Singkatnya, transformasi digital berbasis AI mencakup otomatisasi, penggunaan teknologi AI untuk menyelesaikan tugas-tugas yang tidak ingin dilakukan oleh manusia atau yang tidak dapat dilakukan oleh manusia – seperti yang kita lakukan di masa lalu, pada revolusi industri pertama, kedua, dan ketiga.
Dari alat tenun hingga seni AI
Setiap terjadi suatu revolusi, muncul ketakutan bahwa pekerja manusia akan menjadi usang dan tersingkirkan. Sehingga sebetulnya mengapa ada keinginan dari diri manusia untuk mengotomatisasi suatu pekerjaan? Meskipun dalam beberapa kasus, para penemu teknologi hanya tertarik pada prestasi penemuan itu sendiri, namun lebih seringnya, sebuah penemuan atau pengembangan didorong oleh kepentingan bisnis. Seperti halnya adopsi yang meluas. Dan di era apa pun, jarang ditemukan bisnis yang memiliki tujuan lain selain tetap kompetitif dan meningkatkan keuntungan. Alat tenun stoking atau stocking looms ditemukan pada abad ke-16 untuk meningkatkan produktivitas dan menurunkan biaya operasional dengan menggantikan tenaga kerja manusia. Mesin tenaga uap pada abad ke-19 di industri dan pabrik-pabrik serta mesin pertanian juga digunakan untuk alasan serupa. Robot pembuat kendaraan di pertengahan kedua abad ke-20 juga demikian. Baik teknologi traktor, jalur perakitan, atau spreadsheet, memiliki tujuan utama serupa yaitu untuk menggantikan otot manusia dengan tenaga mekanis, menggantikan pekerjaan tangan manusia dengan konsistensi mesin, dan mengatasi persoalan “humanware” yang lambat dan rentan kesalahan dengan perhitungan digital. Namun sejauh ini, meskipun banyak pekerjaan yang hilang karena otomatisasi, pekerjaan baru lainnya juga bermunculan. Produksi yang meningkat secara besar-besaran membutuhkan pekerjaan yang berkaitan dengan peningkatan distribusi. Pergeseran juga terjadi pada kendaraan seperti mobil penumpang yang telah menggantikan tenaga kuda dan pekerjaan terkait berkuda, serta meningkatkan mobilitas pribadi, pekerjaan justru muncul dari industri kuliner dan akomodasi yang berkembang. Meningkatnya daya komputasi yang digunakan untuk menggantikan tugas-tugas manusia di kantor juga memunculkan produk dan industri gim yang sepenuhnya baru. Selain itu, seiring dengan meningkatnya kekayaan dan pertumbuhan populasi yang menyertai perkembangan tersebut, permintaan akan rekreasi dan konsumsi juga meningkat, sehingga mendorong sektor-sektor ini dan menciptakan lapangan kerja – meskipun tidak sebanyak yang dibayangkan, seperti yang akan kita lihat di bawah ini. Namun, kita tidak bisa berasumsi bahwa revolusi saat ini akan mengikuti pola yang sama dan menciptakan lebih banyak lapangan kerja dan kekayaan daripada yang akan tersingkirkan hanya karena hal ini terjadi di masa lampau. Tidak seperti teknologi mekanik dan komputasi dasar, teknologi AI tidak hanya memiliki potensi untuk menggantikan pekerja berupah rendah saja, misalnya, dengan robot pembersih atau robot pertanian. Akan tetapi, mereka juga mulai mengungguli keahlian para pekerja profesional seperti ahli patologi dalam mendiagnosis kanker dan profesional medis lainnya dalam mendiagnosis dan merawat pasien. Kini, teknologi tersebut juga mengambil alih tugas-tugas kreatif seperti menulis kreatif, memilih adegan untuk trailer film, atau memproduksi seni digital. Kita tidak perlu berasumsi akan masa depan yang suram dengan berkurangnya pekerjaan dan menurunnya angka kekayaan. Namun kita harus ingat bahwa, dalam berbagai kasus, mengganti pekerja berupah tinggi dengan solusi AI saat ini lebih hemat biaya dibandingkan dengan tenaga kerja berupah rendah seperti para pekerja tekstil di Bangladesh.
Oleh karena itu, untuk memperoleh perspektif lain yang sedikit berbeda, mari kita simak klaim-klaim yang paling sering dikemukakan dalam beberapa waktu belakangan ini dan bagaimana klaim-klaim tersebut dapat dipertanggungjawabkan.
Klaim pertama: AI akan mengakibatkan lebih banyak/sedikit pekerjaan yang muncul daripada pekerjaan yang terancam punah
Pernyataan ini merupakan argumen utama yang dikemukakan dalam skenario utopis/distopis, termasuk berdasarkan laporan dari WEF (97 juta pekerjaan baru melawan 85 juta pekerjaan yang hilang di 26 negara pada tahun 2025), PwC (“kehilangan pekerjaan akibat otomasi kemungkinan besar akan diimbangi secara luas untuk jangka panjang oleh pekerjaan baru yang diciptakan”), Forrester (kehilangan pekerjaan sebesar 29% pada tahun 2030 dengan hanya 13% pekerjaan yang dapat dikompensasikan), dan masih banyak lagi. Bagaimanapun juga, setiap perubahan yang terjadi dapat menimbulkan tantangan yang signifikan. Seperti pernyataan BCG dalam laporan terbaru tentang topik ini, “total pekerjaan yang hilang atau bertambah adalah indikator yang sangat sederhana” untuk memperkirakan dampak digitalisasi. Perubahan bersih nol atau bahkan peningkatan jumlah pekerjaan dapat menyebabkan asimetri besar di pasar tenaga kerja dengan kekurangan talenta yang dramatis di beberapa industri atau pekerjaan dan surplus pekerja yang sangat besar serta pengangguran di industri lain. Di sisi lain, alih-alih menyebabkan pengangguran – atau setidaknya underemployment, berkurangnya lapangan pekerjaan juga dapat menyebabkan lebih banyak pembagian pekerjaan dan jumlah jam kerja yang lebih pendek. Sekali lagi, meskipun hal ini mungkin terdengar menarik secara teori, hal ini menimbulkan pertanyaan tambahan: Bagaimana gaji dan tunjangan akan terdampak? Dan siapa yang akan mendapatkan keuntungan moneter terbesar? Apakah perusahaan? Pekerja? Pemerintah? Memang masih terlalu dini untuk melihat dampak adopsi AI yang meluas terhadap pekerjaan atau upah secara keseluruhan. Namun, apa yang dihasilkan di masa lampau yaitu revolusi industri tidak menjamin hasil yang sama di masa mendatang. Bahkan sejarah pun mencatat bahwa pertumbuhan lapangan kerja dan kekayaan tidak semulus yang sering digambarkan. Rasio lapangan kerja terhadap populasi usia kerja telah meningkat di negara-negara OECD sejak tahun 1970, dari 64% menjadi 69% pada tahun 2022. [1] Namun, sebagian besar dari peningkatan ini dapat dikaitkan dengan tingkat partisipasi tenaga kerja yang lebih tinggi, terutama di kalangan perempuan. Dan peningkatan kekayaan ini tentu saja tidak terdistribusi secara merata, misalnya di Amerika Serikat.
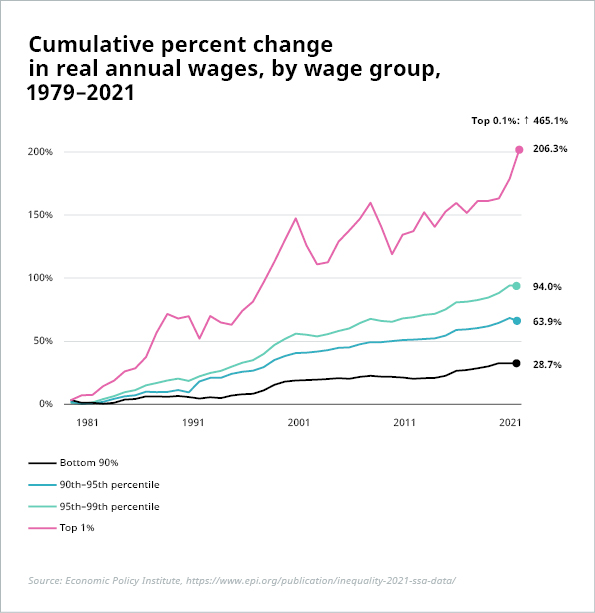
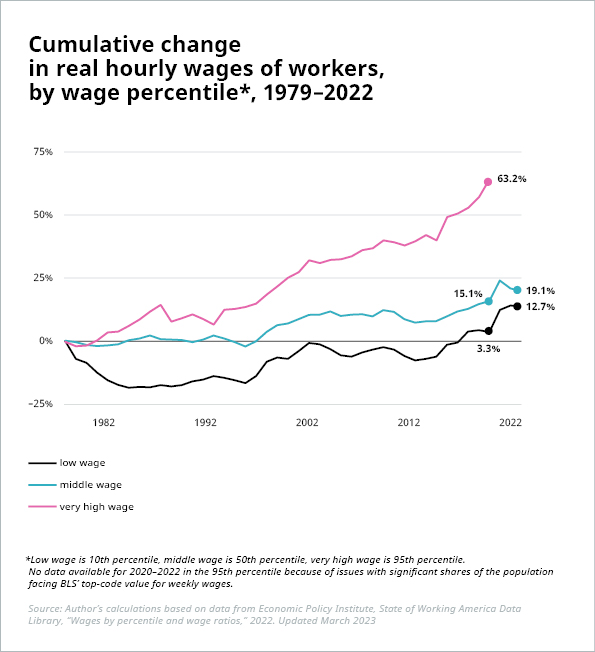
Sumber: Ilustrasi 1: Economic Policy Institute, https://www.epi.org/publication/inequality-2021-ssa-data/; Ilustrasi 2: Perhitungan penulis berdasarkan data dari Economic Policy Institute, State of Working America Data Library, “Upah berdasarkan persentil dan rasio upah,” 2022. Diperbaharui Maret 2023
*Upah rendah adalah persentil ke-10, upah menengah adalah persentil ke-50, upah sangat tinggi adalah persentil ke-95. Tidak ada data yang tersedia untuk tahun 2020–2022 pada persentil ke-95 karena adanya masalah dengan sebagian besar populasi yang menghadapi nilai kode teratas BLS untuk upah mingguan.
Tidak ada alasan untuk menganggap bahwa AI dan otomatisasi akan secara otomatis membuat kita menjadi lebih kaya sebagai masyarakat atau bahwa peningkatan kekayaan akan didistribusikan secara merata. Oleh karena itu, kita harus sama-sama siap menghadapi skenario yang lebih negatif dan mendiskusikan bagaimana cara mengurangi konsekuensinya. Misalnya, apakah proses AI dapat diperlakukan seperti tenaga kerja manusia? Jika ya, maka kita dapat mempertimbangkan untuk pengenaan pajak untuk mendukung redistribusi kekayaan atau untuk membiayai pelatihan atau tunjangan dan pensiun bagi para pekerja yang tergeser.
Selain itu, kita juga perlu mempertanyakan perkiraan perpindahan pekerjaan pada tingkat dasar. Siapa yang dapat dengan yakin menyatakan bahwa pekerjaan ini akan berkurang? Bagaimana kita bisa tahu jenis pekerjaan apa yang akan ada di masa depan? Tidak ada satu pun dari proyeksi ini yang benar-benar dapat diandalkan atau bersifat objektif – proyeksi ini terutama didasarkan pada pendapat sekelompok orang saja. Sebagai contoh, Laporan Masa Depan Pekerjaan WEF, salah satu laporan paling berpengaruh yang mengusung topik ini, didasarkan pada survei pemberi kerja. Namun, sangatlah naif jika kita berpikir bahwa siapa saja, apalagi seorang kader pemimpin perusahaan karbitan, dapat memiliki pemahaman yang begitu yakin dan pasti akan pekerjaan dan keterampilan apa saja yang dibutuhkan di masa depan. Semestinya kita tidak percaya begitu saja layaknya mempercayai sebuah ramalan. Hal ini membawa kita kembali pada prediksi kecanggihan mobil di awal abad ke-19, tren belanja jarak jauh di tahun 1960-an, penemuan ponsel di tahun 1980-an, atau komputer sejak tahun 1940-an. Begitu banyak prediksi teknologi yang telah keliru total – mengapa hal ini harus berubah sekarang? Namun, jenis ramalan bola kristal ini merupakan elemen kunci dalam perkiraan “masa depan pekerjaan”.
Faktanya, penelitian yang kuat secara ilmiah tentang topik ini masih sangat langka. Salah satu dari sedikit makalah di bidang ini mempelajari dampak AI pada pasar tenaga kerja di AS dari tahun 2007 hingga 2018. Para penulis (dari MIT, Princeton, dan Boston University) menemukan bahwa eksposur AI yang lebih besar dalam bisnis dikaitkan dengan tingkat perekrutan yang lebih rendah, yaitu setidaknya hingga saat ini, adopsi AI terkonsentrasi pada substitusi daripada penambahan pekerjaan. Makalah yang sama juga tidak menemukan bukti bahwa efek produktivitas yang besar dari AI akan meningkatkan perekrutan. Beberapa pihak mungkin menganggap bahwa pernyataan ini mendukung pandangan distopia. Namun, penting untuk dicatata bahwa penelitian ini berdasarkan pada data lowongan online, sehingga dengan demikian hasilnya harus diperlakukan secara hati-hati, seperti yang telah dijelaskan secara rinci di salah satu artikel kami. Selain itu, akibat dinamika inovasi dan adopsi teknologi, hampir tidak mungkin untuk mengekstrapolasi dan memproyeksikan temuan-temuan ini untuk membuat prediksi yang cukup meyakinkan bagi perkembangan di masa depan.
Selain itu, secara lebih filosofis, apa manfaat dari keberadaan manusia jika kita bekerja lebih sedikit? Bukankah kegiatan bekerja sudah menjadi hakikat kita; sebagai sifat alamiah manusia yang sesungguhnya.
Klaim kedua: Komputer unggul dalam hal yang dianggap sulit, namun lemah untuk hal yang dianggap mudah
Pertanyaannya adalah, sulit dan mudah bagi siapa? Beruntungnya, kita semua tidak memiliki keunggulan dan kelemahan yang sama, sehingga kita tidak menganggap tugas-tugas yang sama itu “mudah” dan “sulit”. Pernyataan ini hanyalah sebuah generalisasi yang didasarkan pada penilaian yang sepenuhnya subjektif. Dan jika itu benar, maka kebanyakan orang mungkin akan menganggap tugas-tugas yang repetitif biasanya dianggap mudah, atau setidaknya lebih mudah. Hal ini secara langsung bertentangan dengan klaim berikutnya, yaitu:
Klaim ketiga: AI (hanya) akan menghancurkan pekerjaan yang repetitif dan akan menghasilkan pekerjaan yang lebih menarik dan bernilai lebih tinggi.
Forum Ekonomi Dunia atau WEF menyatakan bahwa AI akan mengotomatiskan tugas-tugas repetitif seperti entri data dan produksi lini perakitan, “memungkinkan pekerja untuk fokus pada tugas-tugas yang bernilai lebih tinggi dan memiliki daya tarik yang lebih tinggi” dengan “manfaat bagi bisnis dan individu yang akan memiliki lebih banyak waktu untuk berkreasi, berstrategi, dan berjiwa wirausaha.” BCG berbicara tentang “pergeseran dari pekerjaan dengan tugas-tugas yang repetitif di lini produksi ke bidang pemrograman dan pemeliharaan teknologi produksi” dan bagaimana “penghilangan tugas-tugas yang biasa dan repetitif di bidang hukum, akuntansi, administratif, dan profesi serupa membuka kemungkinan bagi karyawan untuk mengambil peran yang lebih strategis”. Pertanyaannya adalah, siapa yang diuntungkan dari hal ini? Tidak semua pekerja yang dapat melakukan tugas-tugas repetitif memiliki potensi untuk mengambil peran strategis, kreatif dan berwirausaha, atau memprogram dan memelihara teknologi produksi. Faktanya, tidak semua orang dapat dilatih untuk setiap peranan maupun jabatan tertentu. Tugas-tugas yang lebih menyenangkan dan menarik bagi para intelektual (seperti para pendukung masa depan pekerjaan yang lebih cerah berkat AI) mungkin terlalu menantang bagi pekerja yang cenderung tidak terlalu memiliki kecerdasan intelektual yang pekerjaannya – yang sebetulnya tergolong cukup memuaskan bagi mereka – baru saja diotomatisasi. Dan tidak semua pekerja kantoran bisa atau ingin menjadi pengusaha atau ahli strategi. Selain itu, apa sebenarnya arti dari “nilai yang lebih tinggi”? Siapa yang diuntungkan dari hal ini? Pekerjaan baru yang tercipta sejauh ini, seperti pekerja gudang Amazon, atau pengemudi Uber dan layanan pengiriman pos, tidak sepenuhnya memberikan upah yang layak dan terjamin. Terlebih sejak awal tahun 1970-an, perusahaan-perusahaan telah menunjukkan ketidaktertarikan mereka untuk berbagi nilai tambah dari peningkatan produktivitas dengan para pekerja:
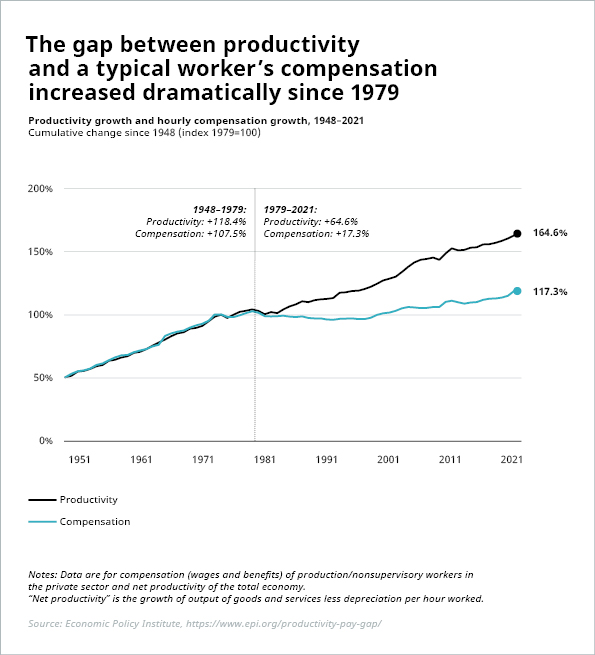
Sumber: Economic Policy Institute, https://www.epi.org/productivity-pay-gap/
Di sisi lain, sejumlah besar aplikasi AI yang ada telah melakukan tugas-tugas yang lebih tinggi tingkat kerumitannya hingga yang sangat terampil berdasarkan penggalian data, pengenalan pola, dan analisis data: diagnosis dan perawatan kondisi medis, chatbot layanan pelanggan, optimasi tanaman dan strategi pertanian, nasihat keuangan atau asuransi, pendeteksi kecurangan, penjadwalan dan perutean dalam logistik dan transportasi umum, riset pasar dan analisis perilaku, perencanaan tenaga kerja, desain produk, dan banyak lagi. Kemudian, ditambah lagi dengan beragam aplikasi ChatGPT. Dampak penuh dari aplikasi-aplikasi ini di pasar kerja masih belum begitu jelas, namun yang pasti, aplikasi-aplikasi ini lebih dari sekadar menggeser tugas-tugas yang biasa dan repetitif dari profil pekerjaan saja.
Klaim keempat: Kita (hanya) perlu melakukan peningkatan/perbaikan keterampilan pekerja
Meskipun tidak sepenuhnya setuju dengan pernyataan ini, namun hal ini sering kali dikemukakan sebagai solusi yang cukup sederhana untuk mempersiapkan diri menghadapi pergeseran pasar tenaga kerja di masa depan yang digerakkan oleh AI dan “merangkul manfaat sosial yang positif dari AI” (WEF). Faktanya, hal ini memiliki beberapa peringatan yang menjadikannya solusi yang jauh dari sederhana.
Pertama, tidak perlu menekankan kembali sebuah keniscayaan bahwa mustahil bagi kita untuk bisa memprediksi “masa depan pekerjaan” dengan tepat, terutama pekerjaan mana yang akan diminati dan mana yang tidak. Selain itu, berdasarkan dampak dari revolusi industri terdahulu dan penelitian saat ini, kemungkinan besar adopsi AI secara luas akan memperkenalkan pekerjaan baru dengan profil yang belum dapat kita antisipasi. Hal ini menunjukkan bahwa kita harus membekali para profesional masa kini dan di masa depan dengan keterampilan yang diperlukan untuk pekerjaan yang saat ini bahkan belum kita ketahui. Salah satu solusi yang lazim diusulkan untuk mengatasi masalah tersebut yaitu dengan mendorong pembelajaran jangka panjang dan mempromosikan bentuk pelatihan dan pendidikan yang lebih mudah diadaptasi dan berjangka pendek. Pilihan ini tentu saja menjadi valid dan semakin populer meskipun kemudian terdapat beberapa aspek yang perlu diingat. Misalnya, 15-20% populasi orang dewasa di Amerika Serikat dan Uni Eropa [2] memiliki kemampuan baca tulis yang rendah (PIAAC level 1 atau di bawahnya), yang berarti mereka memiliki masalah dengan tugas-tugas seperti mengisi formulir atau memahami teks mengenai topik yang tidak familiar. Bagaimana kandidat ini dapat dilatih untuk berhasil dalam “proyek yang lebih kompleks dan bermanfaat” jika mereka tidak dapat membaca buku teks, menavigasi manual, atau menulis laporan sederhana? Selain itu, sekitar 10% pekerja penuh waktu di AS dan Uni Eropa adalah pekerja miskin/working poor. [3] Kelompok individu semacam ini biasanya tidak memiliki cukup waktu, sumber daya, atau dukungan dari pemberi kerja untuk belajar sepanjang hayat dan dengan demikian tidak memiliki akses yang memadai untuk mendapatkan pelatihan yang efisien, tepat sasaran, dan terjangkau.
Ketika isu-isu tersebut dapat diatasi, banyak dari para pekerja tersebut mungkin sudah ketinggalan zaman. Pada tahun 2018, pengusaha AS memperkirakan bahwa lebih dari seperempat tenaga kerja mereka membutuhkan setidaknya tiga bulan pelatihan untuk mengimbangi persyaratan keterampilan yang diperlukan untuk tugas mereka saat ini pada tahun 2022. [4] Dua tahun kemudian, persentase tersebut meningkat dua kali lipat menjadi lebih dari 60%, dan jumlahnya serupa di seluruh dunia. [5] Selain itu, bahkan sebelum periode pasca-Resesi Besar, hanya sekitar 6 dari 10 pekerja AS yang menganggur yang berhasil dipekerjakan kembali dalam waktu 12 bulan pada periode 2000 hingga 2006. [6] Pada tahun 2019, angka ini setara dengan apa yang terjadi di Uni Eropa. [7] Seiring dengan perubahan yang semakin cepat terkait kebutuhan keterampilan, ditambah dengan kurangnya waktu dan/atau sumber daya untuk kelompok rentan seperti pekerja miskin dan pekerja dengan tingkat literasi yang rendah, belum lagi kurangnya jaring pengaman dan langkah-langkah yang ditargetkan dalam sistem pengembangan tenaga kerja yang kekurangan dana, prospek para pekerja tersebut tidak tampak akan membaik dalam waktu dekat.
Selain itu, pandemi secara masif telah mengakselerasi adopsi otomatisasi dan AI di tempat kerja di berbagai sektor. Robot, mesin, dan sistem AI telah digunakan untuk membersihkan lantai, mengukur suhu atau memesan makanan, menggantikan karyawan di tempat makan, loket tol, atau pusat panggilan, berpatroli di real estat yang kosong, meningkatkan produksi industri persediaan rumah sakit, dan masih banyak lagi dalam waktu yang teramat singkat. Dahulu, teknologi baru diterapkan secara bertahap, memberikan cukup waktu bagi karyawan untuk bertransisi ke peran dan tugas mereka yang baru. Kali ini, para pemberi kerja bergegas mengganti pekerja dengan mesin atau perangkat lunak karena adanya aturan lockdown atau pembatasan sosial yang tiba-tiba. Hal ini merupakan perbedaan penting dari revolusi industri yang terjadi sebelumnya dengan apa yang baru-baru ini terjadi. Banyak pekerja yang diberhentikan tanpa cukup waktu untuk berlatih kembali. Peristiwa yang sama mungkin akan terjadi di masa depan – baik itu pandemi lain atau terobosan teknologi – dan sebagai masyarakat, kita harus siap menghadapi peristiwa ini dan memberikan dukungan yang cepat, efisien, dan yang terpenting, realistis terhadap para pekerja yang terdampak.
Klaim kelima: Perusahaan harus melihat up- dan re-skilling sebagai sebuah investasi, bukan sebagai beban.
Jika sebuah perusahaan mengganti semua kasirnya dengan robot, mengapa perusahaan tersebut ingin melatih ulang para pekerja baru yang redundan? Bahkan pemerintah pun mengalami kesulitan untuk mengambil sikap ini dalam hal pelatihan dan pendidikan. Banyak negara yang berfokus pada pendidikan tinggi atau pelatihan lain untuk pekerja muda daripada melatih ulang para pencari kerja atau karyawan. Sebagai contoh, pemerintah AS menghabiskan 0,1% dari PDB untuk membantu para pekerja melewati masa transisi pekerjaan, kurang dari setengah dari yang dihabiskan 30 tahun yang lalu – meskipun tuntutan keterampilan berubah jauh lebih cepat dibandingkan dengan tiga dekade yang lalu. Dan sebagian besar bisnis terutama tertarik untuk memaksimalkan keuntungan – begitulah cara kerja ekonomi kita. Perlu diingat bahwa kita hidup di dunia dimana bahkan seorang penjual makanan dan penjaga hewan peliharaan pun bisa dipaksa oleh majikannya untuk menandatangani perjanjian non-kompetisi agar mereka tidak mendapatkan kenaikan gaji dengan mengancam akan pindah ke pesaing yang memberikan gaji yang lebih tinggi.
Perangkat lunak percakapan atau chatbot yang berkinerja baik dapat menawarkan layanan pusat panggilan yang berkapasitas 1.000 orang bagi perusahaan yang hanya perlu mempekerjakan 100 personel. Dengan demikian, bot dapat merespons 10.000 pertanyaan dalam satu jam, jauh lebih tinggi daripada volume realistis yang dapat ditangani oleh petugas call center yang paling efisien sekalipun. Selain itu, chatbot tidak pernah sakit, tidak membutuhkan cuti, atau meminta tunjangan dan keuntungan. Mereka membuat keputusan yang konsisten dan berdasarkan bukti serta tidak mencuri atau membohongi atasan mereka. Jadi, jika kualitas perangkat lunak ini memadai dengan nilai yang terjangkau, mungkin akan memicu perdebatan di antara para pemegang saham jika sebuah perusahaan menyia-nyiakan tawaran ini. Bagaimanapun juga, solusi yang meningkatkan efisiensi dan produktivitas sekaligus menurunkan biaya adalah sebuah impian yang menjadi nyata bagi perusahaan. Jadi, jika perusahaan tidak melewatkannya maka kompetitornya yang akan mengambil kesempatan ini. Dan terlepas dari propaganda “teknologi untuk kebaikan sosial” yang selalu kita dengar dari Silicon Valley, sebagian besar perusahaan sebetulnya tidak begitu peduli dengan nasib para pekerja yang akan segera pensiun di masa mendatang.
Beyond the bubble
Pada prinsipnya, kita tidak semestinya mendramatisir atau berupaya keras meyakinkan diri sendiri bahwa akan ada cukup banyak lapangan pekerjaan bagi kita, atau kita akan terus mengejar ketertinggalan. Sebagian besar masalah atau solusi yang sering dikemukakan cenderung dibahas secara terbatas di dalam gelembung akademis atau gelembung para peneliti, pengusaha teknologi, dan pembuat kebijakan tingkat tinggi, yang tercampuraduk dalam sejumlah idealisme substantif. Namun, untuk dapat mengikuti perkembangan – baik maupun buruk – yang berpotensi besar dalam mengubah pasar tenaga kerja dan masyarakat secara menyeluruh, kita perlu melihat jauh ke depan dan merancang strategi yang realistis untuk masa depan berdasarkan fakta dan data yang objektif.
[1] https://stats.oecd.org/Index.aspx?DatasetCode=LFS_SEXAGE_I_R#
[2] US: https://www.libraryjournal.com/?detailStory=How-Serious-Is-Americas-Literacy-Problem
EU: http://www.eli-net.eu/fileadmin/ELINET/Redaktion/Factsheet-Literacy_in_Europe-A4.pdf
[3] US: https://nationalequityatlas.org/indicators/Working_poor?breakdown=by-race-ethnicity&workst01=1
EU: https://ec.europa.eu/eurostat/databrowser/view/sdg_01_41/default/table?lang=en
[4] The Future of Jobs Report 2018, World Economic Forum, 2018.
[5] The Future of Jobs Report 2020, World Economic Forum, 2020.
[6] Back to Work: United States: Improving the Re-employment Prospects of Displaced Workers, OECD, 2016.