请不要再把ontology和taxonomy相提并论
对大多人来说,“本体(ontology)”这个词可能听起来很抽象。要了解本体,就要从万维网的发明者伯纳斯∙李(Berners-Lee)的梦想谈起。 他梦想有一天不仅是人类,机器也能读懂整个计算机网络上的数据,包括内容,链接和计算机人员交易(目前网络上的内容只有人类可以读懂,而计算机无法理解和处理),他把这样一个网络叫做语义网(Semantic Web)。为了实现语义网,RDF(资源描述框架)和OWL(Web本体语言)被开发为用于数据和知识的共享及集成的标准格式,其中,有丰富的概念模式的Web本体语言就是我们想要说的本体。[1] 但值得一提的是,在当今的IT世界中,“知识图谱(knowledge graph)”这一术语也广泛用于指代本体这一概念。
为什么要了解本体
在人工智能这个广义范围里,人们近来更多地关注于机器学习,大数据和深度学习,诚然,媒体和某些唯利是图的公司过分夸大了人工智能的真实性。Adrian Bowles在文章中引用到:“如果没有知识的呈现就谈不上机器的智能”。人工智能是建立在知识工程,信息架构和神经网络前的大量的人类的辛勤工作之上的。Alexander Wissner-Gross说,也许当今阻碍机器向强人工智能发展的不是算法 – 而是智能数据集。
“如果没有知识的呈现就谈不上机器的智能。”
本体和语义网有着千丝万缕的联系。人类通常能很容易的理解一个术语,这是因为人类具有相关背景知识甚至仅仅是一些常识。机器自然缺乏这样的能力。但是,机器可以通过本体中概念和其相互关系的链接来“学习”术语背后的语义。强大的本体已经存在于多个特定领域,例如金融商业本体(FIBO),以及在医疗,地理,职业等领域的众多本体。
从语义层面进行推理几乎被人工智能界所淡忘,但其地位实则占据人工智能界的半壁江山。除了类似识别潜在欺诈性交易,进行产品推荐,根据用户的互联网点击确定用户的意图等应用,AI还可以做得更多。机器还应该去探讨更多需要基于问题领域的知识和关于世界的普通常识来进行明确推理的任务,比如了解报纸文章的内容,准备饭菜或是选购汽车。类似的任务需要的不是“输入数据”,而是能以动态组合知识的形式来回答问题和得出结论。只有本体基于其知识的建模方式才能实现这种类型的机器推理。[2]
Taxonomy和Ontology不能相提并论
由于同属专家系统,在谈到ontology时,另一个术语taxonomy(分类法)常常与之混淆。追其来源,这两个术语都是从其它领域被借用到人工智能,语义网,系统工程和信息架构中。然而他们绝非相同。比如,类似O*NET(Occupational Information Network)和ESCO (European Skills/Competences, qualifications and Occupations) 的职业信息分类查询系统就只是taxonomy,他们远远不能和ontology相提并论。
从分类法的角度看,taxonomy算是一个相对ontology而言更简单一些的分类系统,遵循至上而下的层级结构,并在分类中利用“父-子”关系。但是taxonomy系统中没有任何其他实体之间的联系,更谈不上智能关系。打个比方,taxonomy常常被比喻为一棵树,如果我们在这里还是把taxonomy喻为一个树,那么ontology就像是一片森林。
“高尔夫”这个实体可能出现在多个taxonomy中。首先,它可能出现在一个叫做“人类活动”的分类中(人类活动->业余活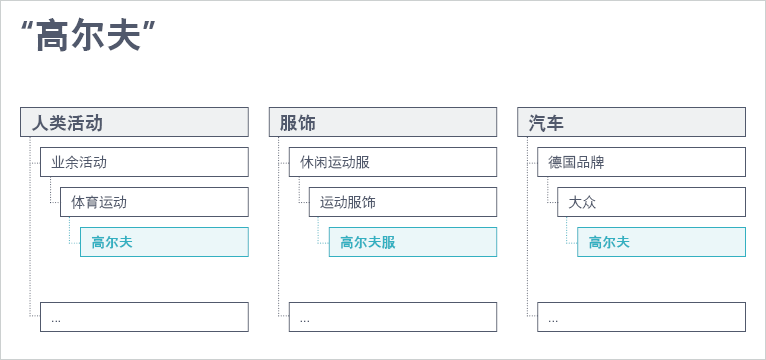 动->体育运动->高尔夫)。它也可能出现在一个关于服饰的分类中(服饰->休闲运动服->运动服饰->高尔夫服)。同时,它还可能出现在一个似乎不太相关的分类中(汽车->德国品牌->大众->高尔夫)。如果把这三个taxonomy看作是三棵不同的树,他们枝叶交汇的节点就是“高尔夫”这个实体。 [3]
动->体育运动->高尔夫)。它也可能出现在一个关于服饰的分类中(服饰->休闲运动服->运动服饰->高尔夫服)。同时,它还可能出现在一个似乎不太相关的分类中(汽车->德国品牌->大众->高尔夫)。如果把这三个taxonomy看作是三棵不同的树,他们枝叶交汇的节点就是“高尔夫”这个实体。 [3]
在taxonomy中,实体之间的联系仅仅能代表“是什么”的关系,然而在ontology中实体间的联系更加丰富,能表达更深的关系,例如“有什么”和“用什么”等。[4] 因此,taxonomy不能实现子关系之间的类比,以ESCO系统为例:
 在ESCO中,几乎所有医学专家都一起归在专科医生下,并且所有医学专家的技能组合被简单地列在一起,而没有将特定技能与某个医学专家联系起来。 为什么? 因为ESCO这样的系统主要以统计为目的, 以得出某年某个行业的从业人数,而没有必要根据每个医学专家的技能和培训背景进一步去分类。 所以,根据taxonomy,只能通过辨别职业名称来判断某个职业具体是干什么的,或是通过查询其它来源更充分的理解某个特定的职业。
在ESCO中,几乎所有医学专家都一起归在专科医生下,并且所有医学专家的技能组合被简单地列在一起,而没有将特定技能与某个医学专家联系起来。 为什么? 因为ESCO这样的系统主要以统计为目的, 以得出某年某个行业的从业人数,而没有必要根据每个医学专家的技能和培训背景进一步去分类。 所以,根据taxonomy,只能通过辨别职业名称来判断某个职业具体是干什么的,或是通过查询其它来源更充分的理解某个特定的职业。
在为职业,资格和技能数据构建ontology时,其强大的功能远远超出单一的统计,而能进行职称区分和相似性识别。以儿科医生和新生儿科医生为例:使用ontology建模方法,可以给出儿科医生和新生儿医生技能组合相似度百分比,尽管这两者的相似性极高,但儿科医生只能在接受特殊培训后才能接管新生儿科医生的工作。所有这些信息都可以通过相互关系映射到ontology中,而在taxonomy中却不能实现。
本体支持匹配数据集
也许您会认为,和taxonomy相比,ontology这些功能也没有什么惊艳之处。但是当要进行匹配时,比如将一组简历与一组空缺职位相匹配,绝对没有优于本体的更好的方法。通常,关键字匹配或满是噱头的模糊的机器学习方法被用来进行此类操作。这意味着许多相似性未被检测到,因为关键字词变体,同义词和替代词不能被识别,从而造成不匹配的结果。本体确保了比较两个项的语义(字面下的含义)而不只是文字排列,从而可以检测简历和职务描述中的潜在含义和相似之处。
本体匹配技术是许多应用中的基本技术,包括本体合并。在具有非常复杂规则的深层领域(以及规则之间复杂的交互)中,如探讨整合不同领域知识的可能性时,本体的优势是无可取代的。例如,在考虑导航或保险风险时,将一个关于天气的本体和另一个关于地理的本体整合成第三个本体,从而大大提升了这两个单独本体的价值。 [5]
本体的真正价值
语义系统依赖于明确的,人类可理解的概念,关系和规则表示来开发所需领域的知识图谱。而完全依赖程序员来构建基于机器学习的系统是不可取的,因为程序员缺乏定义特定领域中概念之间关系所需的知识。因此,必须从具有不同背景领域专家(例如知识产权法,流体动力学,汽车修理,心脏直视手术或教育和职业系统)中学习相关知识。这个过程对于创建全面的知识图谱至关重要。
对于多语种JANZZ本体来说,语言技能是一个关键点。在许多情况下,将概念一对一地翻译成多种语言是不可能的,但是,因为瑞士得天独厚的优势,所有JANZZ本体构建人员都能流利地使用至少两种语言,有些甚至熟练掌握四种以上的语言(包括中文和阿拉伯文)。这一优势保证了JANZZ本体在不同语言中的一致性和质量。
大约十年前,JANZZ科技公司开始在各种职业分类体系的基础上构建自己的本体,其中包括ISCO-08,ESCO和所有国家特定的分类系统。一路走来,JANZZ已经在自己的本体中增加了数千种新的职业和技能(例如市场研究数据挖掘者,千禧代代数专家和社交媒体经理),这些是在任何已有的分类系统中都不存在的。除此之外,JANZZ本体还包括了最新的技能,教育,经验和专业等等。JANZZ本体是人力资源部门和公共就业服务部门最合适的工具,它能识别不同职业之间的相似性和模糊性,远远胜于那些术语集合式的分类系统。如今,JANZZ本体是世界上最大,最复杂,最完整的职业数据本体。
对于试图在基于taxonomy的分类系统和基于ontology的分类系统之间进行选择的人力资源部门和公共就业服务部门,我们希望本文能帮助您做出明智的决策,并帮助您意识到投资于非语义(没有内容)的系统是无长远利益可言的。幸运的是,一些政府和公司已经做出了正确的选择并且已经从我们最新的技术中受益。如果您想了解有关JANZZ本体的更多信息,请立即写信给 sales@janzz.technology
[1] Ian Horrocks. 2008. Ontologies and the Semantic Web. URL: http://www.cs.ox.ac.uk/ian.horrocks/Publications/download/2008/Horr08a.pdf [2019.02.01 ]
[2] Larry Lefkowitz. 2018. Semantic Reasoning: The (Almost) Forgotten Half of AI. URL: https://aibusiness.com/semantic-reasoning-ai/ [2019.02.01]
[3] New Idea Engineering. 2018. What’s the difference between Taxonomies and Ontologies? URL: http://www.ideaeng.com/taxonomies-ontologies-0602 [2019.02.01]
[4] Daniel Tunkelang. 2017. Taxonomies and Ontologies. URL: https://queryunderstanding.com/taxonomies-and-ontologies-8e4812a79cb2 [2019.02.01]
[5] Nathan Winant. 2014. What are the advantages of semantic reasoning over machine learning? URL: https://www.quora.com/What-are-the-advantages-of-semantic-reasoning-over-machine-learning [2019.02.01 ]
